Date mare

În statistică și informatică , termenul englezesc big data („mari [mase de] date” sau în italiană megadate [1] [2] ) indică generic o colecție de date de informații atât de extinse în ceea ce privește volumul, viteza și varietatea încât sunt necesare tehnologii și metode analitice specifice pentru extragerea valorii sau a cunoștințelor [3] . Prin urmare, termenul este folosit în referință la capacitatea (tipică științei datelor ) de a analiza sau extrapola și raporta o cantitate enormă de date eterogene, structurate și nestructurate (datorită metodelor sofisticate de procesare statistică și computerizată), pentru a descoperi linkurile între diferite fenomene (de exemplu corelații ) și prezice viitoare. Datele mari pot fi utilizate pentru o varietate de scopuri, inclusiv măsurarea performanței unei organizații, precum și a unui proces de afaceri. [4]
Descriere

Deși nu există o separare strictă între datele mari și alte date (care nu pot fi clasificate ca mari ), au fost propuse abordări diferite pentru a descrie particularitățile lor. În 2011, Teradata afirmă că „Un sistem de date mari depășește / depășește / depășește sistemele hardware și software utilizate în mod obișnuit pentru a capta, gestiona și prelucra date într-un timp rezonabil chiar și pentru o comunitate masivă / populație de utilizatori”. O altă propunere pentru caracterizarea Big Data a fost dată de McKinsey Global Institute: „Un sistem Big Data se referă la seturi de date a căror dimensiune / volum este atât de mare încât depășește capacitatea sistemelor de baze de date relaționale de a captura, stoca, gestiona și analiza” .
Pentru a vorbi despre date mari, volumul de date trebuie să fie legat de capacitatea sistemului de a dobândi informații deoarece provin din diferitele surse de date care sunt utilizate, prin urmare, un sistem devine mare atunci când volumul de date crește și în același timp timpul crește viteza / fluxul de informații pe care sistemul trebuie să le poată dobândi și gestiona pe secundă. De fapt, în ultimii doi ani a existat o creștere cu 90% a datelor produse în lume, iar companiile ar putea produce zettabytes de date, de exemplu, luând în considerare datele de la senzori, date prin satelit, financiare, telefonice etc.
Creșterea progresivă a dimensiunii seturilor de date este legată de necesitatea analizei pe un singur set de date, cu scopul de a extrage informații suplimentare în comparație cu ceea ce s-ar putea obține analizând serii mici, cu aceeași cantitate totală de date. De exemplu, analiza pentru a testa „stările de spirit” ale piețelor și ale comerțului și, prin urmare, ale tendinței generale a societății și a râului de informații care călătorește și tranzitează prin Internet . Cu datele mari, cantitatea de date este în ordinea zettabytes , sau miliarde de terabytes , [5] prin urmare este necesară o putere de calcul paralelă și masivă cu instrumente dedicate rulate pe zeci, sute sau chiar mii de servere . [6] [7] Big data implică, de asemenea, interrelarea datelor din surse potențial eterogene, adică nu numai date structurate (cum ar fi cele din baze de date ), ci și nestructurate ( imagini , e-mailuri , date GPS , informații provenite din rețelele sociale , etc.).
Definiție și caracteristici

Nu există un prag de referință prestabilit în ceea ce privește dimensiunea, dincolo de care este legitim să vorbim despre Big Data: în general vorbim despre big data atunci când setul de date este atât de mare și complex încât necesită definirea unor noi instrumente și metodologii să extrapoleze, să gestioneze și să proceseze informații într-un timp rezonabil. [8] De fapt, după cum demonstrează legea lui Moore , evoluția tehnologică permite stocarea și gestionarea seturilor de date cu dimensiuni în continuă creștere [9] . Într-un studiu din 2001 [10] , analistul Douglas Laney definise modelul de creștere ca fiind tridimensional (modelul "3V" [11] [12] ): în timp volumul (datelor), viteza și varietatea (datelor) ). În multe cazuri, acest model este încă valabil, deși a fost extins ulterior [13] [14] [15] [16] .
În primul model al lui Douglas Laney, numit „3V” [12] , cele trei cuvinte cheie au următoarea semnificație:
- Volum : se referă la cantitatea de date (structurate sau nestructurate) generate în fiecare secundă. Aceste date sunt generate de surse eterogene, cum ar fi: senzori, jurnale, evenimente [ neclare ] , e-mail, rețele sociale și baze de date tradiționale;
- Varietate : se referă la diferitele tipuri de date care sunt generate, acumulate și utilizate. Înainte de era Big Data, datele structurate în principal erau luate în considerare pentru analiză; manipularea acestora a fost realizată prin utilizarea bazelor de date relaționale. Pentru a avea analize mai precise și mai profunde, astăzi este, de asemenea, necesar să se ia în considerare:
- a) date nestructurate (de exemplu, fișiere text generate de mașini industriale sau jurnale de server web sau firewall );
- b) date semi-structurate (de exemplu un act notarial cu fraze fixe și variabile) pe lângă datele structurate (de exemplu un tabel de baze de date);
- Viteză : se referă la viteza cu care sunt generate noile date. Nu numai că viteza de generare a datelor este importantă, ci și necesitatea ca aceste date / informații să ajungă într- un sistem în timp real pentru a efectua analize asupra acestora.

De-a lungul timpului, a fost introdus un al patrulea V [13] [14] , cel al veridicității, apoi un al cincilea, cel al Valorii [15] [16] .
- Adevăr : având în vedere varietatea datelor sursă (date structurate sau nestructurate) și viteza cu care aceste date pot varia, este foarte probabil că nu este posibil să se garanteze aceeași calitate a datelor de intrare pentru sistemele de analiză disponibile în mod normal în ETL-urile tradiționale. . Este evident că, dacă datele care stau la baza analizelor sunt inexacte, rezultatele analizelor nu vor fi mai bune. Deoarece deciziile se pot baza pe aceste rezultate, este esențial să se atribuie un indice de veridicitate datelor pe care se bazează analizele, pentru a avea o măsură de fiabilitate [17] .
- Valoare : se referă la capacitatea de a transforma datele în valoare. Un proiect Big Data necesită investiții, chiar și semnificative, pentru colectarea granulară a datelor și analiza acestora. Înainte de a începe o inițiativă, este important să evaluați și să documentați care este valoarea reală adusă afacerii [15] .
De-a lungul timpului, au fost adăugate caracteristici suplimentare modelului, cum ar fi:
- variabilitate: această caracteristică poate fi o problemă și se referă la posibilitatea incoerenței datelor;
- complexitate: cu cât este mai mare dimensiunea setului de date, cu atât este mai mare complexitatea datelor care trebuie gestionate. [ necesită citare ] [18] [19] [20]
Alte modele conceptuale, cum ar fi Modelul ITMI (Informații, Tehnologie, Metode, Impact) [21] [22] , au încercat să reprezinte într-un mod sintetic diferitele aspecte care caracterizează fenomenul big data în complexitatea sa, mergând dincolo de caracteristicile datei, așa cum este cazul pentru modelele bazate pe „V”.
Creșterea volumului de date

Big Data este un subiect interesant pentru multe companii [23] , care în ultimii ani au investit peste 15 miliarde de dolari în această tehnologie, finanțând dezvoltarea de software pentru gestionarea și analiza datelor. Acest lucru s-a întâmplat deoarece cele mai puternice economii sunt foarte motivate să analizeze cantități uriașe de date: gândiți-vă doar că există peste 4,6 miliarde de smartphone-uri active și aproximativ 2 miliarde de persoane au acces la Internet . Din 1986 volumul de date în circulație a crescut exponențial:
- în 1986 cifrele erau de 281 Petabytes ;
- în 1993 cifrele erau de 471 PetaBytes;
- în 2000 cifrele erau de 2,2 Exabytes ;
- în 2007 cifrele erau de 65 ExaByte;
- pentru 2014 se aștepta un schimb de peste 650 ExaBytes [24] [25] .
Diferențe cu business intelligence

Maturitatea crescândă a conceptului de Big Data evidențiază diferențele cu business intelligence , în ceea ce privește datele și utilizarea acestora:
- Business intelligence folosește statistici descriptive cu date cu densitate mare de informații pentru a măsura lucrurile, a detecta tendințele etc., adică folosește seturi de date limitate, date curate și modele simple; [26]
- Big Data utilizează statistici inferențiale și concepte de identificare a sistemelor neliniare [27] , pentru a deduce legi (cum ar fi regresii , relații neliniare și efecte cauzale ) din seturi mari de date [28] ; pentru a dezvălui relații și dependențe între ele și pentru a face predicții ale rezultatelor și comportamentelor [27] [29], adică folosește seturi de date eterogene ( fără legătură ), date brute și modele predictive complexe. [26] [30]
Modele de analiză a datelor
Așa cum s-a spus anterior, volumul de date Big Data și utilizarea extinsă a datelor nestructurate nu permit utilizarea sistemelor tradiționale pentru gestionarea bazelor de date relaționale ( RDBMS ), dacă nu prin tehnici de structurare. Datele structurate stocate în sistemele tradiționale RDBMS permit o performanță infinit mai bună, în cercetare, decât sistemele NoSQL , garantând coerența datelor, ceea ce în sistemele Big Data nu este în general garantată. Prin urmare, sistemele Big Data nu trebuie considerate complementare bazelor de date, ci mai degrabă un set de tehnici ETL pe structuri nestructurate și generat într-un mod geografic foarte distribuit [ neclar ] . Participanții la piață folosesc mai degrabă sisteme foarte scalabile și soluții bazate pe NoSQL. În domeniul analizei de afaceri , au fost create noi modele de reprezentare care sunt capabile să gestioneze această cantitate de date cu prelucrarea paralelă a bazelor de date. Arhitecturi de procesare distribuite cu seturi de date mari sunt oferite de Google MapReduce și omologul open source Apache Hadoop . Pe baza instrumentelor și modelelor utilizate pentru analiza și gestionarea datelor, este posibil să se distingă patru metode (sau tipuri) de Big Data Analytics:

- Analiza descriptivă , setul de instrumente care vizează descrierea situației actuale și anterioare a proceselor de afaceri și / sau a zonelor funcționale. Aceste instrumente vă permit să accesați datele interactiv (de exemplu, prin introducerea de filtre sau efectuarea operațiunilor de detaliere ) și pentru a vizualiza principalii indicatori de performanță într-un mod sintetic și grafic (toate organizațiile mari folosesc acest tip);
- Analiza predictivă , instrumente avansate care efectuează analiza datelor pentru a răspunde la întrebări legate de ceea ce s-ar putea întâmpla în viitor (sunt caracterizate prin tehnici matematice precum regresia, prognozarea , modelele predictive etc.);
- Analiza prescriptivă , instrumente avansate care, împreună cu analiza datelor, sunt capabile să propună soluții operaționale / strategice pe baza analizelor efectuate;
- Analize automate , instrumente capabile să implementeze independent acțiunea propusă în conformitate cu rezultatele analizelor efectuate. [31]
Tehnologii de stocare și procesare

Cantitatea tot mai mare de date generate de surse de date eterogene a concentrat atenția asupra modului de extragere, arhivare și utilizare a acestora pentru a obține profit. Problema întâmpinată se datorează în principal dificultății gestionării Big Data cu baze de date tradiționale, atât din punct de vedere al costurilor, cât și din punct de vedere al volumului. Combinația acestor elemente a condus la dezvoltarea de noi modele de procesare, care au permis companiilor să devină mai competitive, atât printr-o reducere a costurilor, cât și pentru că noile sisteme sunt capabile să stocheze, să transfere și să combine date cu date mai rapide și mai agile . Pentru a gestiona sistemul Big Data, sunt utilizate sisteme care distribuie atât resurse, cât și servicii:
- Arhitecturi distribuite : utilizarea clusterelor de calculatoare conectate între ele pentru a coopera pentru a atinge un obiectiv comun prin atingerea scalabilității orizontale (nu verticale).
- Toleranță la erori : arhitecturile / platformele propuse trebuie proiectate astfel încât să fie tolerante la erori, astfel încât resursele să fie reproduse pe diferitele mașini care alcătuiesc clusterul.
- Calcul distribuit : Modelul de calcul este distribuit pentru a profita de puterea de calcul a clusterului proiectat.
Pentru a gestiona cantități mari de date, au fost propuse noi metodologii în următoarele domenii:
Pentru a sprijini aceste metodologii, au fost propuse următoarele tehnologii și limbaje de programare:
- NoSQL
- Hadoop Framework ( HDFS , MapReduce , Hive , Hbase , Spark , Tez, Storm, Mahout etc.);
- R și Python .
Ciclu de viață
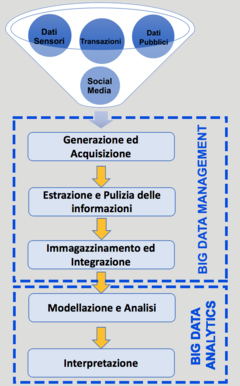
Extragerea cunoștințelor din Big Data și utilizarea acesteia pentru îmbunătățirea activităților de luare a deciziilor sunt subordonate definiției proceselor care permit gestionarea și transformarea eficientă a seturilor de date care cresc rapid în volum și varietate. Fiecare fază a fiecărui proces modifică starea și conținutul aceluiași, ajutând la conversia alunecelor de date încă brute în valoare și, prin urmare, la îmbogățirea modelului analitic al datelor [32] [33] [34] . Aceste procese constituie o referință pentru alegerea sau crearea unei arhitecturi, adică o structură logică și fizică care determină modul în care Big Data trebuie stocat, accesat și gestionat în cadrul unei organizații. De asemenea, specifică soluțiile care trebuie puse în aplicare pentru a face față problemelor care pot apărea din tratarea Big Data, cum ar fi calitatea scăzută a datelor sau scalabilitatea infrastructurilor, componentelor hardware și software, cum ar fi cadrele și bazele de date. informații, confidențialitate și securitate a datelor și multe altele.
Principalele procese care alcătuiesc ciclul de viață al Big Data pot fi grupate în două macro-zone:
- Gestionarea Big Data : include procesele și tehnologiile pentru achiziționarea și stocarea Big Data și pregătirea și recuperarea acestora;
- Analiza Big Data : conține procesele utilizate pentru a analiza și a obține informații utile din seturi de date mari pentru a interpreta și descrie trecutul ( analize descriptive ), pentru a prezice viitorul ( analize predictive ) sau pentru a recomanda acțiuni ( analize prescriptive ) [35] .
Generare și achiziție
Pe lângă varietatea de formate și structuri, Big Data prezintă și o varietate de surse. Datele generate de acestea sunt adesea clasificate în:
- generate de oameni : sunt găsite și derivă în special din platformele de rețele sociale ( Facebook , LinkedIn ), blogging ( Blogger , Wordpress ) și micro-blogging ( Twitter , Tumblr ), știri sociale ( Digg , Reddit ), marcaje sociale ( Delicious , StumbleUpon ), partajare multimedia ( Instagram , Flickr , YouTube ), wikis ( Wikipedia ), site-uri de întrebări și răspunsuri ( Yahoo Answers ), site-uri de recenzii ( Yelp , TripAdvisor ), portaluri de comerț electronic ( eBay , Amazon ), faceți clic pe flux [ neclar ] de pe site-uri web etc., în general gestionate de cookie-uri .
- generate de mașini : sunt produse de surse precum senzori GPS , IoT , RFID , stații de monitorizare pentru evenimente meteorologice, instrumente științifice, sisteme de tranzacționare de înaltă frecvență de pe piețele financiare, dispozitive biomedicale și altele.
- afaceri generate : ne referim la toate acele date, generate de oameni sau de mașini, generate intern de o companie care înregistrează toate activitățile bazate pe date ale proceselor de afaceri ale companiei. Multe dintre ele sunt date istorice, stocate static în baze de date relaționale, reprezentând plăți, comenzi, producție, inventar, vânzări și date financiare. Producția în creștere a acestui tip de date a făcut necesară utilizarea tehnologiilor și instrumentelor de analiză în timp real, astfel încât companiile să își poată exploata pe deplin potențialul.

Achiziționarea Big Data din aceste canale de informații poate avea loc în diferite moduri:
- Prin accesarea API-urilor puse la dispoziție de serviciile Web, datorită cărora este posibilă interfața cu acestea pentru a le examina conținutul. Exemple sunt API-ul Twitter, API-ul Facebook Graph și API-urile furnizate de motoarele de căutare precum Google și Bing ;
- Folosind software-ul de răzuire web care efectuează operațiuni de crawlere , analiză și extragere a entităților pentru colectarea automată a datelor din documentele de pe Internet. Cadrul Apache Tika, de exemplu, automatizează aceste operațiuni pentru metadate și textul care provin din diferite tipuri de documente, chiar și identificarea limbii lor;
- Importul de date din baze de date relaționale, non-relaționale sau din alte surse cu instrumente ETL , deja utilizate pe scară largă pentru gestionarea datelor în sistemele Data Warehousing și Data Mart . Unul dintre cele mai utilizate instrumente ETL din perspectiva Big Data este Apache Sqoop care vă permite să importați și să exportați cantități mari de date din baze de date relaționale și nu pe platforma Apache Hadoop și invers;
- Prin achiziționarea de fluxuri continue de date, generate rapid, prin sisteme capabile să capteze evenimente, să le proceseze și să le salveze într-o bază de date într-un mod eficient. Tehnologiile populare includ Apache Flume , Apache Kafka și Microsoft StreamInsight .
După achiziționarea din surse, seturile de date sunt transferate către sistemele de stocare locale sau la distanță prin intermediul mijloacelor de transmisie de mare viteză. Setul de date brute, structurate și nestructurate se numește un lac de date , gata de procesare [36] . Mai mult, este esențial să se efectueze operațiuni de precompilare ulterioare, al căror scop este de a filtra datele din informațiile redundante, inexacte sau incomplete pentru a reduce entropia acestora (adică tulburarea), îmbunătățind astfel precizia analizelor și reducând spațiul necesar depozitării acestora.
Extragerea și curățarea informațiilor
Majoritatea datelor colectate nu sunt disponibile în formatul necesar pentru faza de procesare ulterioară. De exemplu, fișierul computerului unui pacient din spital constă în cele mai multe cazuri din rapoarte medicale, rețete, citiri achiziționate de la senzori și / sau mașini de monitorizare și date de imagine, cum ar fi raze X. În acest context, nu este posibil să se utilizeze aceste date în mod eficient atunci când fiecare dintre ele are propria reprezentare. Prin urmare, trebuie să creați un proces de extracție care să preia informațiile solicitate din sursa mare de date și să le reprezinte într-o formă standard, structurată, pregătită pentru analiză. Proiectarea procesului de extracție depinde în principal de zona de aplicare; de exemplu, datele extrase din suporturile utilizate pentru rezonanța magnetică sunt diferite de cele utilizate pentru imaginile stelelor. Mai mult, Big Data poate conține unele informații false. De exemplu, pacienții pot ascunde în mod intenționat unele simptome care pot duce medicul la diagnosticarea greșită a stării lor. Prin urmare, este necesar să se utilizeze tehnici de curățare a datelor care includ constrângeri pentru verificarea validității datelor și a modelelor de eroare pentru a se asigura calitatea acestora.
Depozitare și integrare
Stocarea Big Data este o problemă care derivă din două nevoi: stocarea și organizarea unor seturi de date uriașe nestructurate sau semi-structurate și în același timp garantarea disponibilității acestora și capacitatea de a interacționa cu ele într-un mod fiabil, rapid și sigur. Pentru a satisface aceste nevoi, dezvoltarea infrastructurilor hardware pentru arhivare a fost, de asemenea, combinată cu crearea de mecanisme pentru gestionarea acestor date, în special sisteme de fișiere distribuite și noi tipuri de baze de date.
Infrastructura care suportă Big Data constă din seturi de noduri de stocare și procesare distribuite pe rețea, conectate prin rețele de comunicații de mare viteză, capabile de scalare orizontală și configurate dinamic în funcție de aplicații. Sistemele de fișiere distribuite au sarcina de a oferi o vizualizare unificată a infrastructurii de memorie distribuită subiacentă, oferind operațiuni de bază pentru citirea și scrierea secvențială a unor cantități mari de date, asigurând performanțe ridicate și în același timp un nivel adecvat de toleranță la erori. Cele mai populare sisteme de fișiere distribuite sunt Google File System (GFS) și Hadoop Distributed File System (HDFS). De-a lungul anilor au fost propuse diferite tipuri de baze de date cu scopul de a stoca, gestiona și organiza seturi de date caracterizate prin diferite dimensiuni, structuri și origini. Datorită naturii statice a structurilor de masă, soluțiile bazate pe RDBMS s-au dovedit improprii pentru cerințele de varietate și volum ale Big Data.
Prin urmare, organizarea logică a datelor este încredințată bazelor de date NoSQL care abandonează restricțiile impuse de modelul relațional și de limbajul SQL, dar care, în schimb, posedă caracteristici fundamentale pentru Big Data, cum ar fi „ schemaless ” și distribuite, având date de replicare ușoare, eventuală consecvență și, nu în ultimul rând, suportul de memorie persistent pentru cantități mari de date. Faza de stocare este adesea însoțită de o fază de integrare care constă în prelucrarea și transformarea ulterioară a datelor pentru a le pregăti pentru faza de analiză ulterioară. Acest lucru permite obținerea unei vizualizări unificate și normalizate a datelor. Operațiunile care se desfășoară cel mai frecvent în această fază sunt unirea datelor din baze de date externe și recunoașterea conținutului textual din documente provenind din surse precum Web sau depozite corporative.
Modelare, prelucrare și analiză

Scopul fazei de analiză este de a extrage valoare sub formă de cunoștințe din Big Data, examinând seturile de date uriașe disponibile pentru a descoperi corelații, tendințe, tipare și alți indici statistici ascunși în date. Analizele pot fi efectuate pe date structurate, semi-structurate și nestructurate, inclusiv:
- Analiza textului : extragerea de informații și cunoștințe din textul nestructurat conținut în documente, e-mailuri, pagini web și postări de blog și rețele sociale, cunoscut și sub denumirea de minerit de text, utilizează în principal tehnici de procesare a limbajului natural (NLP)), învățare automată și analiză statistică. Datorită acestor algoritmi au fost dezvoltați pentru recunoașterea subiectelor (modelarea subiectelor), căutarea celor mai bune răspunsuri la o întrebare (răspuns la întrebări), identificarea opiniilor utilizatorilor cu privire la anumite știri (opinie mining) și altele;
- Analiza datelor multimedia : natura nestructurată a conținutului multimedia, cum ar fi imaginile, videoclipurile și sunetul, dimensiunea, eterogenitatea și faptul că sunt produse foarte rapid, le fac potrivite pentru a face față sistemelor Big Data Analytics. Algoritmii de învățare automată permit extragerea informațiilor de nivel scăzut și înalt utile pentru descrierea semantică a fișierelor multimedia. Adnotarea automată prin etichete textuale (adnotarea multimedia) și extragerea caracteristicilor vizuale sau sonore (extragerea caracteristicilor) sunt activități la baza algoritmilor de indexare (indexare multimedia) și recomandare (recomandare multimedia) a acestor conținuturi.
- Analiza web : este posibil să se obțină informații și cunoștințe despre conținutul, structura și utilizarea Webului prin analizarea automată a paginilor și a hyperlinkurilor. Analiza conținutului textual și multimedia se realizează folosind tehnicile menționate mai sus. Topologia poate fi reconstruită folosind algoritmi de accesare cu crawlere care urmează hyperlinkuri pentru a dezvălui relații între pagini sau site-uri web. Unul dintre cei mai cunoscuți algoritmi inspirați de acest mecanism este PageRank-ul Google. Profilarea utilizării web de către un utilizator din ce în ce mai divers se realizează prin examinarea unui număr mare de jurnale de server, sesiuni, tranzacții, căutări și vizite pentru a personaliza experiențele individuale ale utilizatorilor.
Minarea datelor, învățarea automată și tehnicile de analiză statistică, cum ar fi clusterizarea, corelarea și regresia, sunt aplicate Big Data prin utilizarea modelelor de programare și a cadrelor de procesare distribuite care vă permit să obțineți rapid informații agregate din bazele de date NoSQL sau din alte surse, similar cu ce se întâmplă pentru limbajul SQL cu baze de date relaționale. Acestea din urmă sunt clasificate în funcție de actualitatea necesară pentru analize (analize în timp real sau batch) și posibilitatea de a accelera o parte din operațiuni prin încărcarea sau nu a datelor în memoria primară (în analiza memoriei). Printre cele mai populare modele de programare se numără MapReduce, parte a cadrului Apache Hadoop, care permite procesarea în serie și în paralel a unor seturi mari de date pe clustere de mașini de uz general folosind paradigma omonimă și Google Pregel care vă permite să efectuați procesare distribuită pe grafice uriașe care pot reprezintă, de exemplu, grafice ale rețelelor de calculatoare sau ale relațiilor dintre utilizatorii unei rețele sociale.
Interpretarea rezultatelor și luarea deciziilor
Interpretarea parametrilor analizați poate oferi sugestii pentru a verifica ipoteze empirice asupra fenomenelor de interes, pentru a lua decizii de afaceri mai eficiente, pentru a identifica piețe noi în care să investească, pentru a dezvolta campanii științifice de marketing științifice și pentru a îmbunătăți eficiența operațională.
Dispute
Dezvoltarea recentă a metodologiilor pentru achiziționarea și prelucrarea unor cantități mari de date prin intermediul algoritmilor implică toate sectoarele economice și a ridicat îndoieli cu privire la aplicarea lor în absența unor reglementări și controale adecvate. În 2008 , în urma crizei economice globale , doi ingineri financiari, Emanuel Derman și Paul Wilmott, au elaborat un manifest etic pentru oamenii de știință de date , după modelul Jurământului hipocratic pentru medici [37] . În 2017 , cercetătorul de date Cathy O'Neil a expus într-o carte diferitele probleme care au apărut cu utilizarea modelelor bazate pe Big Data. Molti dei quali, lungi dall'essere equi ed obiettivi, si sono dimostrati codificazioni di pregiudizi umani che hanno portato ad errori sistemici senza possibilità di appello nei software che controllano le nostre vite in diversi ambiti, da quello legale a quello lavorativo e politico [38] . Il pericolo di rendere la vita delle persone "calcolabile" sulla base delle tracce che ciascuno lascia in rete, è affrontato in un saggio di Domenico Talia , che discute più in generale dei rischi e delle relazioni tra l'uso dei Big Data, la privacy dei cittadini e l'esercizio della democrazia. [39]
A differenza dell' America Settentrionale , il Parlamento Europeo ha già varato un Regolamento generale sulla protezione dei dati [40] . Secondo Kevin Kelly , «se si vuole modificare il comportamento in Rete delle persone, basta semplicemente alterare sullo schermo gli algoritmi che lo governano, che di fatto regolano il comportamento collettivo o spingono le persone in una direzione preferenziale» [41] [42] .
Nei primi mesi del 2018 è scoppiato loscandalo Facebook : una società che analizza Big Data, Cambridge Analytica , ha usato i dati personali di 87 milioni di utenti della rete sociale a scopo di propaganda politica [43] . Nello scandalo, è emerso che la società britannica abbia utilizzato i big data per influenzare le persone in occasione di elezioni in diversi Paesi anche per il presidente degli Stati Uniti tenutesi nel novembre 2016. Facebook è stato accusato degli standard morali che le società di social networking avrebbe dovuto seguire e della maggiore protezione dei media online e della privacy che ogni utente online dovrebbe avere [ Frase poco chiara. ] [44] . Pertanto, nell'aprile 2018 Facebook ha pagato una multa di 5 miliardi di dollari e dovuto applicare alla propria piattaforma il regolamento generale sulla protezione dei dati.
Virtualizzazione dei Big Data
La virtualizzazione dei Big Data è un modo per raccogliere dati da poche fonti in un singolo livello. Il livello dati raccolto è virtuale. A differenza di altri metodi, la maggior parte dei dati rimane sul posto e viene presa su richiesta direttamente dai sistemi di origine. [45]
Note
- ^ Voce 3551299 nella IATE .
- ^ ( EN ) megadati - Translation in English — TechDico , su www.TechDico . URL consultato il 19 luglio 2019 .
- ^ ( EN ) Andrea De Mauro, Marco Greco e Michele Grimaldi, A Formal definition of Big Data based on its essential features , in Library Review , vol. 65, n. 3, 2016, pp. 122-135, DOI : 10.1108/LR-06-2015-0061 . URL consultato il 25 giugno 2017 .
- ^ Alberto Sardi, Enrico Sorano, Valter Cantino, Patrizia Garengo, Big data and performance measurement research: trends, evolution and future opportunities , in Measuring Business Excellence , 2020, DOI : 10.1108/MBE-06-2019-0053 .
- ^ Marco Russo, Luca De Biase, Che cosa pensereste se vi dicessero che in Italia i Big Data non esistono? , su blog.debiase.com . URL consultato il 28 ottobre 2014 .
- ^ ( EN ) Jacobs, A., The Pathologies of Big Data , su queue.acm.org , ACMQueue, 6 luglio 2009. URL consultato il 21 ottobre 2013 .
- ^ Gianluca Ferrari, Il vero significato dei "Big data" , su searchcio.techtarget.it , 14 giugno 2011. URL consultato il 21 ottobre 2013 .
- ^ Snijders, C., Matzat, U., & Reips, U.-D. (2012). 'Big Data': Big gaps of knowledge in the field of Internet. International Journal of Internet Science, 7 , 1-5. International Journal of Internet Science, Volume 7, Issue 1
- ^ De Mauro, Andrea., Big data analytics : guida per iniziare a classificare e interpretare dati con il machine learning , Apogeo, 2019, ISBN 9788850334780 , OCLC 1065010076 . URL consultato il 10 novembre 2019 .
- ^ Douglas Laney, 3D Data Management: Controlling Data Volume, Velocity and Variety ( PDF ), su blogs.gartner.com , Gartner. URL consultato il 6 febbraio 2001 .
- ^ Mark Beyer, Gartner Says Solving 'Big Data' Challenge Involves More Than Just Managing Volumes of Data , su gartner.com , Gartner. URL consultato il 13 luglio 2011 ( archiviato il 10 luglio 2011) .
- ^ a b ( EN ) Mark Beyer, Gartner Says Solving 'Big Data' Challenge Involves More Than Just Managing Volumes of Data , su gartner.com . URL consultato il 25 giugno 2017 ( archiviato il 10 luglio 2011) .
- ^ a b ( EN ) What is Big Data? , su villanovau.com , Villanova University .
- ^ a b ( EN ) IBM, The Four V's of Big Data , su ibmbigdatahub.com , ibm, 24 agosto 2012. URL consultato il 25 giugno 2017 ( archiviato il 24 agosto 2012) .
- ^ a b c ( EN ) Why only one of the 5 Vs of big data really matters , in IBM Big Data & Analytics Hub . URL consultato il 18 agosto 2017 .
- ^ a b ( EN ) The 5 Vs of Big Data - Watson Health Perspectives , in Watson Health Perspectives , 17 settembre 2016. URL consultato il 18 agosto 2017 .
- ^ ( EN ) Data Veracity , su www.datasciencecentral.com . URL consultato il 16 agosto 2017 .
- ^ Big Data , su assoknowledge.org , ASSOKNOWLEDGE Confindustria Servizi Innovativi e Tecnologici. URL consultato il 9 giugno 2018 ( archiviato il 9 giugno 2018) .
- ^ BIG DATA , su logisticaefficiente.it . URL consultato il 9 giugno 2018 ( archiviato il 9 giugno 2018) .
- ^ Big Data , su multimac.it . URL consultato il 9 giugno 2018 ( archiviato il 9 giugno 2018) .
- ^ ( EN ) Andrea De Mauro, Marco Greco e Michele Grimaldi, Understanding Big Data Through a Systematic Literature Review: The ITMI Model , in International Journal of Information Technology & Decision Making , vol. 18, n. 04, 2019-7, pp. 1433-1461, DOI : 10.1142/S0219622019300040 . URL consultato il 10 novembre 2019 .
- ^ Allard J. van Altena, Perry D. Moerland e Aeilko H. Zwinderman, Understanding big data themes from scientific biomedical literature through topic modeling , in Journal of Big Data , vol. 3, n. 1, 15 novembre 2016, p. 23, DOI : 10.1186/s40537-016-0057-0 . URL consultato il 10 novembre 2019 .
- ^ ( EN ) Elisabetta Raguseo, Big data technologies: An empirical investigation on their adoption, benefits and risks for companies , in International Journal of Information Management , vol. 38, n. 1, 2018-2, pp. 187-195, DOI :10.1016/j.ijinfomgt.2017.07.008 . URL consultato il 23 ottobre 2019 .
- ^ ( EN ) Economist, Data, data everywhere , su economist.com .
- ^ ( EN ) M. Hilbert e P. Lopez, The World's Technological Capacity to Store, Communicate, and Compute Information , in Science , vol. 332, n. 6025, 1º aprile 2011, pp. 60-65, DOI : 10.1126/science.1200970 . URL consultato il 10 novembre 2019 .
- ^ a b I Big Data vi parlano. Li state ascoltando? ( PDF ), su italy.emc.com , EMC , 2012. URL consultato il 22 ottobre 2013 .
- ^ a b ( EN ) Billings SA "Nonlinear System Identification: NARMAX Methods in the Time, Frequency, and Spatio-Temporal Domains". Wiley, 2013
- ^ ( FR ) Delort P., Big data Paris 2013
- ^ ( FR ) Delort P., Big Data car Low-Density Data? La faible densité en information comme facteur discriminant
- ^ ( EN ) Rasetti M., Merelli E., The Topological Field Theory of Data: a program towards a novel strategy for data mining through data language
- ^ Alessandro Piva, Come impostare un progetto di Big Data Analytics? . URL consultato il 21 giugno 2018 .
- ^ ( EN ) Han Hu, Yonggang Wen, Tat-Seng Chua e Xuelong Li, Toward Scalable Systems for Big Data Analytics: A Technology Tutorial , in IEEE Access , vol. 2, 2014, pp. 652-687, DOI : 10.1109/ACCESS.2014.2332453 .
- ^ ( EN ) Chen, Min and Mao, Shiwen and Liu e Yunhao, Big Data: A Survey , in Mobile Networks and Applications , vol. 19, 2014, pp. 171-209, DOI : 10.1007/s11036-013-0489-0 .
- ^ ( EN ) Nasser Thabet e Tariq Rahim Soomro, Big Data Challenges , in Journal of Computer Engineering & Information Technology} , 2015, DOI : 10.4172/2324-9307.1000133 .
- ^ ( EN ) James R. Evans e Carl H. Lindner, Business Analytics: The Next Frontier for Decision Sciences , in Decision Lines , vol. 43, n. 2.
- ^ https://www.mdirector.com/it/marketing-digitale/cos-e-un-data-lake.html
- ^ https://www.uio.no/studier/emner/sv/oekonomi/ECON4135/h09/undervisningsmateriale/FinancialModelersManifesto.pdf
- ^ Cathy O'Neill, Weapons of Math destruction , Penguins Book, 2016; Armi di distruzione matematica, Come i Big Data aumentano la disuguaglianza e minacciano la democrazia , Bompiani, 2016, ISBN 978-88-452-9421-1 .
- ^ Domenico Talia, La società calcolabile ei Big Data , Rubbettino, 2018, ISBN 978-8849851823
- ^ http://www.lsoft.com/resources/optinlaws.asp
- ^ Kevin Kelly , The Inevitable (2016), L'inevitabile, le tendenze tecnologiche che rivoluzioneranno il nostro futuro (2017) Milano, Il Saggiatore, trad. Alberto Locca, ISBN 978-88-428-2376-6 , pag. 94.
- ^ Yuval Noah Harari, Why Technology Favors Tyranny , in The Atlantic , 2018-10. URL consultato l'11 marzo 2019 .
- ^ https://www.ilfattoquotidiano.it/2018/04/04/facebook-zuckerberg-testimoniera-alla-commissione-usa-l11-aprile-sul-caso-cambridge-analytica/4270478/
- ^ The Cambridge Analytica scandal changed the world – but it didn't change Facebook , su theguardian.com .
- ^ ( EN ) What is Data Virtualization? , su www.datawerks.com . URL consultato il 27 aprile 2018 (archiviato dall' url originale il 10 aprile 2018) .
Bibliografia
- Andrea De Mauro, Big Data Analytics. Analizzare e interpretare dati con il machine learning , ISBN 978-8850334780 , Apogeo, 2019.
- Marco Delmastro, Antonio Nicita, Big Data. Come stanno cambiando il nostro mondo, Il Mulino, 2019.
- Stefano Mannoni, Guido Stazi , Is Competition A Click Away? Sfida al monopolio nell'era digitale, Editoriale scientifica 2018.
- Viktor Mayer-Schonberger, Kenneth Cukier, Big Data: A Revolution That Will Transform How We Live, Work and Think , John Murray Publishers Ltd, 2013; Big data. Una rivoluzione che trasformerà il nostro modo di vivere e già minaccia la nostra libertà , Garzanti, 2013, ISBN 978-8811682479 .
- Marc Dugain, Christophe Labbé, L'uomo nudo. La dittatura invisibile del digitale , ISBN 978-88-99438-05-0 , Enrico Damiani Editore, 2016.
- Alessandro Rezzani, Big data. Architettura, tecnologie e metodi per l'utilizzo di grandi basi di dati , ISBN 978-8838789892 , Apogeo Education, 2013.
- Cathy O'Neill, Weapons of Math destruction , Penguins Book, 2016; Armi di distruzione matematica, Come i Big Data aumentano la disuguaglianza e minacciano la democrazia , Bompiani, 2016, ISBN 978-88-452-9421-1 .
Voci correlate
- Analisi dei dati
- Big data analytics
- Data warehouse
- Business intelligence
- Data mining
- Machine learning
- NoSQL
- Apache Hadoop
- MapReduce
- Internet delle cose
- Cookie
- Cloud computing
- Privacy
- Open Data
- Serie storiche
- Profilazione dell'utente
- Cambridge Analytica
Altri progetti
-
 Wikimedia Commons contiene immagini o altri file su big data
Wikimedia Commons contiene immagini o altri file su big data
Collegamenti esterni
| Controllo di autorità | Thesaurus BNCF 56394 · LCCN ( EN ) sh2012003227 · GND ( DE ) 4802620-7 · BNF ( FR ) cb16657853j (data) · BNE ( ES ) XX5324756 (data) · NDL ( EN , JA ) 001147262 |
|---|