Listă legată
În informatică , o listă legată (sau listă legată) este o dinamică a structurii datelor , inclusiv cele utilizate în programarea de bază. Acesta constă dintr-o secvență de noduri, fiecare conținând câmpuri de date arbitrare și una sau două referințe („ link-uri ”) care indică nodul următor și / sau anterior. O listă legată este un tip de date cu referință automată, deoarece conține un indicator către alte date de același tip. Listele legate permit inserarea și eliminarea nodurilor în fiecare punct al listei în timp constant, dar nu permit accesul aleator, ci doar accesul secvențial. Există mai multe tipuri de liste legate: liste simple , liste dublă și liste circulare .
Listele legate pot fi implementate în multe limbaje de programare . Limbi precum Lisp și Scheme au deja această structură de date în interiorul lor, precum și diverse operațiuni de accesare a conținutului său. Limbajele de procedură, cum ar fi C , C ++ și Java, se bazează de obicei pe indicatori editabili pentru a crea liste legate.
Istorie
Listele legate au fost elaborate în 1955-56 de Allen Newell , Cliff Shaw și Herbert Simon în RAND Corporation ca structură de date fundamentală pentru limbajul lor de procesare a informațiilor . IPL a fost folosit de autori pentru a dezvolta primele programe de inteligență artificială , care includeau Mașina de teorie a logicii, Solverul general de probleme și programul de șah. Publicații despre munca lor au apărut în IRE Transactions on Information Theory în 1956 și în concluziile mai multor conferințe din 1957-1959, inclusiv Proceedings of Western Joint Computer Conference din 1957 și 1958 și Processing Information . UNESCO on Information Information) din 1959 Diagrama acum clasică a blocurilor care reprezintă noduri de listă cu săgeți îndreptate spre noduri de listă ulterioare a apărut în „Programarea mașinii de teorie a logicii” de la Newell și Shaw în Proc. WJCC, în februarie 1957 . Newell și Simon au fost onorați cu premiul ACM Turing în 1975 pentru „contribuțiile de bază la inteligența artificială, înțelegerea psihologiei umane și dezvoltarea listei”.
Problema traducerii automate pentru procesarea limbajului natural l-a determinat pe Victor Yngve de la Massachusetts Institute of Technology (MIT) să utilizeze listele legate ca structuri de date în limbajul său de programare COMIT , care a fost creat pentru cercetarea computerizată în domeniul lingvisticii . Un articol despre acest limbaj intitulat „Un limbaj de programare pentru traducerea mecanică” a apărut în Traducerea mecanică în 1958 .
Lisp , care înseamnă procesor de liste , a fost creat de John McCarthy în 1958 în timp ce lucra la MIT, iar în 1960 a publicat elementele de bază ale limbajului într-un articol din Comunicări al revistei ACM , intitulat „Funcții recursive ale expresiilor simbolice și calculul lor prin mașină, „Porniți”. Una dintre principalele structuri de date ale LISP este lista legată.
La începutul anilor 1960 , utilizarea listelor și limbilor legate care le susțineau ca mod de reprezentare a datelor era acum obișnuită. Bert Green de la Laboratorul Lincoln al MIT a publicat un articol intitulat „Limbaje computerizate pentru manipularea simbolurilor” în IRE Transactions on Human Factors in Electronics în martie 1961 în care a rezumat beneficiile unei abordări de listă legată. Un articol ulterior, „O comparație a limbajelor computerizate de prelucrare a listelor” de Bobrow și Raphael, a apărut în Comunicările ACM în aprilie 1964 .
Diferite sisteme de operare dezvoltate de consultanții tehnici de sisteme (inițial din West Lafayette Indiana, apoi din Raleigh , Carolina de Nord ) au folosit liste legate ca structuri de fișiere. O intrare de director a indicat primul sector al unui fișier, iar porțiunile ulterioare au fost localizate printr-o listă de indicatori. Sistemele care utilizează această tehnică au inclus Flex (pentru procesorul Motorola 6800 ), mini-Flex (același procesor ) și Flex9 (pentru procesorul Motorola 6809 ). O variantă dezvoltată de TSC și comercializată de Smoke Signal Broadcasting în California a folosit același concept cu o listă dublu legată.
Sistemul de operare TSS, dezvoltat de IBM pentru mașinile System 360/370 , a folosit o listă dublă legată pentru a-și gestiona sistemul de fișiere. Structura directorului era similară cu Unix, în care un director putea conține fișiere și / sau alte directoare și extins la orice adâncime. Un program de purici ( flea ) a fost creat pentru a remedia problemele sistemului de fișiere după un accident, deoarece porțiuni modificate ale fișierului se aflau în memorie în momentul problemei. Aceste erori au fost corectate prin compararea legăturilor cu elementul anterior și următorul. Dacă un link a fost corupt și dacă a fost găsit linkul corect, lista a fost corectată (era o listă dublă legată cu două copii ale indicatorului). Un comentariu comic din codul sursă a spus „Toată lumea știe că un apelant de purici scapă de bug-uri la pisici”.
Variante
Liste conectate liniar
Liste simplu conectate
Cea mai simplă modalitate de a crea o listă legată este o listă legată pur și simplu (sau abrevierea slist ), care utilizează un link pe nod. Această legătură indică următorul nod din listă sau o valoare nulă sau o listă goală dacă este valoarea finală.
O listă pur și simplu legată care conține trei valori întregi
Liste dublu legate
Un tip mai sofisticat de listă legată este o listă dublă legată sau o listă legată în două direcții . Fiecare nod are două legături: unul indică spre nodul anterior sau spre o valoare nulă sau către o listă goală dacă este primul nod; celelalte indică nodul următor sau o valoare nulă sau o listă goală dacă este nodul final.

Un exemplu de listă dublă legată.
În unele limbaje de nivel foarte scăzut, listele legate XOR oferă o modalitate de a implementa o listă dublă legată folosind un singur cuvânt pentru ambele linkuri, deși utilizarea acestei tehnici este de obicei descurajată.
Liste legate circular
Într-o listă legată circular , nodul de început și de sfârșit sunt conectate. Acest lucru poate fi implementat fie pentru liste simplu sau dublu conectate. Pentru a parcurge o listă legată circular, puteți începe de la orice nod și urmați lista în ambele direcții până când reveniți la nodul original. Văzut în alt mod, listele legate circular nu au început și nici sfârșit. Acest tip de listă este util pentru gestionarea bufferelor de date și în cazurile în care aveți un obiect în listă și doriți să derulați toate celelalte obiecte din listă. Pointerul care indică întreaga listă se numește de obicei pointerul final.

Listă simplă circulară
Listele circulare pur și simplu concatenate
Într-o listă circulară simplu legată, fiecare nod are un link, similar cu lista normală legată simplu , cu excepția faptului că următorul link din ultimul nod indică primul. La fel ca o listă pur și simplu legată, noile noduri pot fi inserate eficient numai după ce un nod a fost referit. Din acest motiv, este util să păstrați o referință doar la ultimul element dintr-o listă circulară simplu legată, deoarece permite o inserare rapidă la început și, de asemenea, un acces la primul nod prin pointer la următorul nod al ultimului unu.
Listele circulare sunt dublu legate
Într-o listă circulară dublă legată, fiecare nod are două legături, similar cu lista dublă legată , cu excepția faptului că legătura anterioară din primul nod indică ultimul nod și următoarea legătură din ultimul nod indică primul. La fel ca o listă dublă legată, inserarea și ștergerea se pot face în orice moment.
Noduri santinelă
Listele conectate au uneori un nod fals special sau un nod santinelă la începutul și / sau sfârșitul listei care nu este utilizat pentru stocarea datelor. Scopul său este de a simplifica sau accelera unele operații, asigurându-se că fiecare nod care conține datele are întotdeauna un nod anterior și / sau următor și că fiecare listă (chiar și cele care nu conțin date) are întotdeauna un „prim” și un „ultim nodul "". Lisp are un astfel de design - valoarea specială nil este utilizată pentru a marca sfârșitul unei liste „proprii” sau a unui lanț de celule contravine, pur și simplu legat atunci când este apelat. O listă nu trebuie să se termine cu zero, dar o astfel de listă se numește „necorespunzătoare”.
Aplicații ale listelor legate
Listele legate sunt utilizate ca element de construcție pentru multe alte structuri de date, cum ar fi stive , cozi și alte variante. Câmpul „date” al unui nod poate fi o altă listă legată. Datorită acestui truc, puteți construi alte structuri de date cu liste; această practică își are originea în Lisp , unde listele legate sunt o structură primară de date (deși nu sunt singurele) și este acum o caracteristică frecvent utilizată în limbajele de programare funcționale.
Uneori listele legate sunt utilizate pentru a implementa vectori asociativi și sunt numite liste asociative în acest context. Este puțin de spus despre aceste liste; acestea nu sunt foarte eficiente și sunt, chiar și pe seturi de date mici, mai puțin eficiente decât structurile de date bazate pe arbori sau tabele hash . Cu toate acestea, uneori o listă legată este creată dinamic dintr-un subset de noduri dintr-un arbore și este utilizată pentru a traversa un set mai eficient.
Avantajele și dezavantajele în raport cu alte structuri de date
Așa cum se întâmplă adesea în programare și proiectare, nicio metodă nu se potrivește bine tuturor circumstanțelor. O listă legată poate funcționa bine în unele cazuri, dar poate provoca probleme în altele. Există o listă cu avantajele și dezavantajele comune ale listelor conectate. În general, dacă utilizați o structură de date dinamică, unde există elemente care sunt adăugate și șterse frecvent și locația noilor elemente adăugate este importantă, beneficiul unei liste conectate crește.
Liste și vectori conectați
| Vector | Listă legată | |
|---|---|---|
| Adresare | O (1) | O ( n ) |
| Inserare | O ( n ) | O (1) |
| Anulare | O ( n ) | O (1) |
| Persistenţă | Nu | Da individual |
| Locație | Grozav | Rău |
Listele legate au diferite avantaje față de tablouri . Elementele pot fi plasate pe liste la nesfârșit, în timp ce un vector se va umple în curând și va trebui redimensionat, o operațiune costisitoare care poate să nu fie posibilă dacă memoria este fragmentată. În mod similar, un vector în care sunt eliminate multe elemente trebuie să fie micșorat.
Este posibil să salvați memorie suplimentară, în unele cazuri, partajând aceeași „coadă” de elemente între două sau mai multe liste - adică listele vor avea aceeași secvență finală de elemente. În acest fel puteți adăuga elemente noi în partea de sus a listei păstrând în același timp o referință atât la versiunea nouă, cât și la cea veche - acesta este un exemplu simplu de structură de date persistentă .
Pe de altă parte, în timp ce matricile permit accesul aleatoriu , listele legate permit doar accesul secvențial la elemente. De fapt, listele simple conectate pot fi parcurse într-o singură direcție, făcându-le nepotrivite pentru aplicații în care este util să căutați rapid un element folosind indexul său, ca în cazul heapsortului . Accesul secvențial este, de asemenea, mai rapid în matrici decât în listele conectate de pe multe mașini, datorită prezenței referințelor locale și a cache-urilor de date. Listele conectate nu primesc aproape niciun beneficiu din memoria cache.
Un alt dezavantaj al listelor legate este excesul de spațiu necesar pentru stocarea referințelor, ceea ce le face impracticabile pentru listele de articole mici, cum ar fi caracterele și valorile booleene . Alocarea memoriei, efectuată separat pentru fiecare element nou, ar fi lentă și aproximativă: problema este rezolvată dacă se utilizează pool-ul de memorie .
Există mai multe variante ale listelor legate care încearcă să rezolve unele dintre problemele menționate mai sus.
O listă legată derulată (listă legată derulată) stochează mai multe elemente în fiecare nod al listei, crescând performanța în cache și scăzând cheltuielile de memorie datorită stocării referințelor. Codificarea CDR face ambele, înlocuind referințele cu datele de referință.
Listele legate derulate stochează diferitele elemente din fiecare nod, crescând performanța cache-ului și scăzând cheltuielile de memorie pentru referințe. Codificarea CDR face ambele, înlocuind referințele cu date, care se extind dincolo de sfârșitul înregistrării de referință.
Un bun exemplu care evidențiază avantajele și dezavantajele utilizării listelor conectate față de tablouri se găsește în dezvoltarea unui program care rezolvă problema lui Giosefo . Problema lui Giosefo este o metodă de alegere care funcționează prin a avea un grup de oameni adunați într-un cerc. Începând cu o anumită persoană, trebuie să numărăm în jurul cercului de n ori. Odată ce ajungeți la a n-a persoană, o excludeți din cerc, apoi numărați din nou în jurul cercului la fel de n repetând procesul, până când rămâne o singură persoană: câștigătorul. Acest exemplu arată bine punctele tari și punctele slabe ale listelor conectate față de tablouri. Văzând oamenii ca noduri într-o listă circulară legată, este clar cât de ușor poate fi șters unul (ar fi suficient să schimbați legătura nodului anterior). Pe de altă parte, lista ar fi ineficientă pentru a găsi următoarea persoană care urmează să fie eliminată: fiecare eliminare implică derularea listei de n ori. Dimpotrivă, o matrice ar fi ineficientă în ștergerea elementelor, la fiecare ștergere ar trebui să fie mutat fiecare element în urma celui șters, dar invers foarte eficient în găsirea celei de-a n-a persoane din cerc, adresându-se direct elementului corespunzător prin index.
Dublu și simplu înlănțuit
Listele duble legate necesită mai mult spațiu pe nod (cu excepția cazului în care se folosește xor-linking ), iar operațiunile lor elementare sunt mai scumpe; dar există adesea modalități mai ușoare de a le manipula, deoarece permit accesul secvențial la listă în ambele direcții. În special, puteți insera sau șterge un nod cu un număr constant de operații, având doar adresa nodului. Unii algoritmi necesită acces în ambele direcții. Pe de altă parte, nu permite partajarea cozii și nu poate fi folosit ca o structură de date persistentă.
Liste cu legături circulare și liste cu legături liniare
Listele legate circular sunt cele mai utile pentru descrierea structurilor circulare naturale și au avantajul că sunt o structură obișnuită și vă permit să parcurgeți lista începând din orice punct. De asemenea, permit accesul rapid la primul și ultimul nod printr-un singur pointer (adresa ultimului element). Principalul lor dezavantaj este complexitatea iterației, pe care unele cazuri speciale sunt dificil de gestionat.
Noduri santinelă
Nodurile Sentinel pot simplifica operațiunile din anumite liste. asigurându-se că nodul anterior și / sau următorul există pentru fiecare element. Cu toate acestea, nodurile santinelă folosesc spațiu suplimentar (în special în aplicațiile care utilizează o mulțime de liste scurte) și pot complica alte operații.
Operații pe liste legate
Când manipulați listele conectate la fața locului, asigurați-vă că nu utilizați nicio valoare care ar fi putut fi invalidată ca urmare a operațiilor anterioare. Acest lucru face ca algoritmii pentru inserarea sau ștergerea nodurilor listei conectate să fie oarecum subtile. Această secțiune conține pseudocodul pentru adăugarea sau eliminarea nodurilor dintr-o listă legată simplu, dublu sau circular pe loc. Vom folosi nul pentru a ne referi la un indicator de sfârșit de listă sau la o santinelă, care ar putea fi implementat într-o varietate de moduri.
Liste conectate liniar
Liste simplu conectate
Structura noastră de date va avea două câmpuri. De asemenea, păstrăm o variabilă firstNode care indică întotdeauna primul nod din listă sau este nulă pentru o listă goală
înregistrare nod {
date // Datele care trebuie stocate în nod
următor // O referință la nodul următor; nul pentru ultimul nod
}
lista de înregistrări {
Node firstNode // indică primul nod din listă; nul pentru o listă goală
}
Parcurgerea unei liste simplu conectate este simplă; începe de la primul nod și urmează fiecare legătură ulterioară până când ajunge la final:
nod: = list.firstNode
în timp ce nodul nu este nul {
(faceți ceva cu node.data)
nod: = nod.next
}
Următorul cod inserează un nod după un nod existent într-o listă pur și simplu legată. Diagrama arată cum are loc inserarea. Nu este posibil să introduceți un nou nod înainte de altul existent; în schimb, este necesar să o poziționăm ținând cont de cea anterioară.
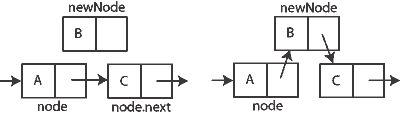
funcție insertAfter ( Node nod, Node newNode) { // insert newNode după nod
newNode.next: = node.next
node.next: = newNode
}
Inserarea la începutul listei necesită o funcție separată, deoarece primul nod firstNode trebuie actualizat.
function insertBeginning ( List list, Node newNode) { // insert nod inainte de primul nod curent
newNode.next: = list.firstNode
list.firstNode: = newNode
}
În mod similar, există funcții pentru a elimina nodul după un anumit nod și pentru a elimina un nod la începutul listei. Diagrama demonstrează prima cale. Pentru a găsi și a elimina un anumit nod, trebuie să țineți evidența elementului anterior.

funcția removeAfter ( Nod nod) { // eliminați nodul după aceasta
obsoleteNode: = nod.next
node.next: = node.next.next
distruge Nodul învechit
}
function removeBeginning ( List list) { // elimina primul nod
obsoleteNode: = list.firstNode
list.firstNode: = list.firstNode.next // indică următorul nod al celui șters
distruge Nodul învechit
}
Rețineți că removeBeginning () stabilește list.firstNode la nul prin eliminarea ultimul nod din listă.
Deoarece nu este posibil să reveniți înapoi, nu sunt posibile operațiuni eficiente precum „insertBefore” (introduceți mai întâi) sau „removeBefore” (eliminați mai întâi).
Adăugarea unei liste conectate la alta este în mod similar ineficientă, deoarece trebuie să parcurgeți întreaga listă pentru a găsi coada și apoi adăugați a doua listă la ea. Deci, dacă două liste liniar legate sunt de lungime , adăugarea unei liste are o complexitate asimptotică de . În limbile Lisp și derivate, adăugarea unei liste este dată de procedura de append .


Liste dublu legate
Cu liste dublu conectate, există și mai multe pointeri de actualizat, dar sunt necesare și mai puține informații, deoarece putem folosi pointeri înapoi pentru a privi elementele anterioare din listă. Aceasta permite operațiuni noi și elimină funcțiile pentru cazuri speciale. Vom adăuga la nodurile noastre un domeniu anterioare care trimit la elementul anterior și la structura listă un câmp lastNode, care indică întotdeauna la ultimul nod din listă. Atât câmpurile list.firstNode și list.lastNode sunt nule pentru o listă goală.
înregistrare nod {
date // Datele care trebuie stocate în nod
next // Un pointer către următorul nod; nul pentru ultimul nod
prev // Un indicator către nodul anterior; nul pentru primul nod
}
lista de înregistrări {
Node firstNode // indică primul nod din listă; nul pentru listele goale
Node lastNode // indică ultimul nod din listă; nul pentru listele goale
}
Iterarea printr-o listă dublă legată se poate face în ambele direcții.
Iterație înainte
nod: = list.firstNode
în timp ce nodul ≠ nul
<faceți ceva cu node.data>
nod: = nod.next
Iterare înapoi
nod: = list.lastNode
în timp ce nodul ≠ nul
<faceți ceva cu node.data>
nod: = nod.prev
Următoarele două funcții sunt perfect simetrice și adaugă un nod înainte sau după o dată cunoscută, așa cum se arată în următoarea diagramă:

funcție insertAfter ( Listă listă, nod nod, nod nou nod )
newNode.prev: = nod
newNode.next: = node.next
dacă node.next = nul
list.lastNode: = newNode
altceva
node.next.prev: = newNode
node.next: = newNode
funcție insertBefore ( Listă listă, nod nod, nod nou nod )
newNode.prev: = nod.prev
newNode.next: = nod
dacă node.prev este nul
list.firstNode: = newNode
altceva
node.prev.next: = newNode
nod.prev: = newNode
De asemenea, avem nevoie de o funcție care să insereze un nod la începutul unei liste, eventual, goale:
funcție inserare Început ( Listă listă, Nod nouNod)
dacă list.firstNode = nul
list.firstNode: = newNode
list.lastNode: = newNode
newNode.prev: = nul
newNode.next: = nul
altceva
insertBefore (list, list.firstNode, newNode)
O funcție simetrică introduce nodul la sfârșitul listei:
funcție insertEnd ( Listă listă, Nod nouNod)
dacă list.lastNode = nul
insertBeginning (list, newNode)
altceva
insertAfter (list, list.lastNode, newNode)
Eliminarea unui nod este mai ușoară, necesită doar atenție cu primul și ultimul nod din listă:
eliminare funcție ( Listă listă, nod nod)
if node.prev = nul
list.firstNode: = nod.next
altceva
node.prev.next: = node.next
dacă node.next = nul
list.lastNode: = node.prev
altceva
node.next.prev: = node.prev
distruge nodul
O consecință subtilă a acestei proceduri este că ștergerea ultimului element dintr-o listă setează atât Node și LastNode pe Null și, astfel, permite eliminarea corectă a ultimului nod din lista unui element. Rețineți că nu aveți nevoie de metode separate „removeBefore” sau „removeAfter”, deoarece într-o listă dublă legată putem folosi „remove (node.prev)” sau „remove (node.next)”.
Liste legate circular
Listele legate circular pot fi legate individual sau dublu. Într-o listă legată circular, toate nodurile sunt conectate într-un cerc continuu, fără a utiliza valoarea nulă . Pentru listele cu un început și un sfârșit (cum ar fi o coadă), o referință este stocată la ultimul nod din listă. Următorul (următorul) nod după ultimul este primul nod. Elementele pot fi adăugate la sfârșitul listei și eliminate de la început în timp constant.
Fiecare tip de listă legată circular beneficiază de faptul că este posibil să parcurgeți întreaga listă într-un timp constant începând de la orice nod. Acest lucru de multe ori vă permite să evitați stocarea firstNode (primul nod) și lastNode (ultimul nod), cu toate că în cazul în care lista este de a fi golit aveți nevoie de o reprezentare specială pentru lista goală, astfel încât un puncte variabile lastNode la un nod din lista sau nul dacă lista este goală; prin urmare, folosim lastNode în acest caz. Această reprezentare simplifică în mod semnificativ adăugarea și eliminarea nodurilor cu o listă care nu este goală, dar listele goale sunt un caz special.
Listele legate circular sunt structura de date preferată a lui Anders Hejlsberg , creatorul LINQ .
Listele dublu legate circular
Presupunând că someNode este un nod generic dintr-o listă care nu este goală, acest cod repetă această listă începând de la someNode :
Iterație înainte
nod: = someNode
do
faceți ceva cu node.value
nod: = nod.next
în timp ce nodul ≠ someNode
Iterare înapoi
nod: = someNode
do
faceți ceva cu node.value
nod: = nod.prev
în timp ce nodul ≠ someNode
Rețineți că testul se face la sfârșitul ciclului. Este important în cazul în care lista conține doar nodul unic someNode .
Această funcție simplă introduce un nod într-o listă dublă legată circular după un anumit element:
funcție insertAfter ( nod nod, nod nou nod )
newNode.next: = node.next
newNode.prev: = nod
node.next.prev: = newNode
node.next: = newNode
Pentru a avea un „insertBefore”, pur și simplu punem „insertAfter (node.prev, newNode)”. Inserarea unui element într-o listă care poate fi goală necesită o funcție specială:
funcție insertEnd ( Listă listă, nod nod)
dacă list.lastNode = nul
nod.prev: = nod
nod.next: = nod
altceva
insertAfter (list.lastNode, nod)
list.lastNode: = nod
Pentru a insera la început folosim un simplu "insertAfter (list.lastNode, nod)". În cele din urmă, pentru a elimina un nod, trebuie să ne ocupăm de cazul în care lista este goală:
eliminare funcție ( Listă listă, nod nod)
if node.next = nod
list.lastNode: = nul
altceva
node.next.prev: = node.prev
node.prev.next: = node.next
dacă nod = list.lastNode
list.lastNode: = node.prev;
distruge nodul
La fel ca în listele dublu conectate, „removeAfter” și „removeBefore” pot fi implementate cu „remove (list, node.prev)” și „remove (list, node.next)”.
Aplicații ale listelor legate folosind vectori de noduri
Limbile care nu acceptă niciun fel de referință pot crea legături prin înlocuirea indicatorilor cu indicii matrice. Abordarea este de a utiliza o matrice de înregistrări, în care fiecare înregistrare are un câmp întreg care indică indexul următorului (și, eventual, anterior) nodului din matrice. Nu trebuie utilizate toate nodurile din matrice. Dacă nici înregistrările nu sunt acceptate, se pot utiliza tablouri paralele.
De exemplu, luați în considerare următoarea listă legată care folosește tablouri în loc de indicatori:
înregistrare intrare {
întreg întreg următor; // indexul următoarei intrări din matrice
număr întreg prev; // intrare anterioară (dacă lista este dublă legată)
numele șirului ;
echilibru real ;
}
Prin crearea unei matrice a acestor structuri și a unei variabile întregi care stochează indexul primului element, se poate construi o listă legată:
lista întreagăHead ; Înregistrări de intrare [1000];
Legăturile dintre elemente sunt create prin inițializarea câmpurilor Următorul sau Prev cu indexul celulei următoare (sau anterioară) pentru fiecare element dat. De exemplu
| Index | Următorul | Anterior | Nume | Echilibru |
|---|---|---|---|---|
| 0 | 1 | 4 | Jones, John | 123,45 |
| 1 | -1 | 0 | Smith, Joseph | 234,56 |
| 2 (listHead) | 4 | -1 | Adams, Adam | 0,00 |
| 3 | Ignoră, Ignatie | 999,99 | ||
| 4 | 0 | 2 | Altul, Anita | 876,54 |
| 5 | ||||
| 6 | ||||
| 7 |
În exemplul de mai sus, ListHead ar trebui să fie setat la 2, indexul primului nod din listă. Rețineți că indexul 3 și indexul 5-7 nu fac parte din listă. Aceste celule sunt disponibile pentru adăugări la listă. Prin crearea unei variabile întregi ListFree , ar trebui creată o listă gratuită pentru a urmări ce celule sunt disponibile. Se tutti gli indici sono in uso, la dimensione dell'array dovrebbero essere incrementate o dovrebbero essere eliminati alcuni elementi per far posto ai nuovi che verrebbero inseriti nella lista.
Il seguente codice dovrebbe scorrere la lista e mostrare i nomi ei bilanci:
i := listHead;
while i >= 0 { '// scorri la lista
print i, Records[i].name, Records[i].balance // print entry
i = Records[i].next;
}
Di fronte ad una scelta, i vantaggi di questo approccio includono:
- Le liste concatenate sono rilocabili, significa che possono essere spostate in memoria a piacere e possono essere direttamente e velocemente serializzate per essere immagazzinate su disco o trasferite via rete.
- Specialmente per le piccole liste, gli array indicizzati possono occupare molto meno spazio di una lista a puntatori in molte architetture.
- La località della referenza può essere migliorata legando i nodi in memoria e periodicamente riordinandoli, tuttavia questo è possibile anche con uno store generale.
- allocatori dinamici della memoria naif possono produrre un eccessivo ammontare di overhead nella memoria per ogni nodo allocato; quasi nessun overhead è prodotto con questo approccio.
- Andare a prendere un elemento da un array pre-allocato è più veloce che utilizzare l'allocazione dinamica della memoria per ogni nodo, dal momento che l'allocazione dinamica della memoria tipicamente richiede una ricerca di blocchi di memoria liberi delle dimensioni desiderate.
Questo tipo di approccio ha molti svantaggi: crea e maneggia uno spazio privato di memoria per il suoi nodi. Questo conduce ai seguenti problemi:
- Incrementa la complessità dell'implementazione.
- Ingrandire un grande array quando è pieno può essere difficile o impossibile, mentre trovare spazio per un nuovo nodo in memoria è più facile.
- Aggiungere elementi ad un array dinamico alle volte (quando è pieno) può avere tempi lineari ( O (n)) invece che costanti (nonostante sia una costante ammortizzata ).
- Usando un memory pool generale permette di lasciare più memoria per gli altri dati se la lista è più piccola del previsto o se molti nodo sono liberati.
Per queste ragioni, questo approccio è usato principalmente per quei linguaggi che non supportano l'allocazione dinamica della memoria. Questi svantaggi sono mitigati dal fatto che la lunghezza massima della lista è conosciuta nel momento in cui viene creato l'array.
Implementazione nei linguaggi
Molti linguaggi di programmazione come il Lisp e Scheme utilizzano liste semplicemente concatenate come strutture dati base del linguaggio. In molti altri linguaggi funzionali , queste liste sono costruite tramite nodi, ciascuno chiamato un cons o una cella cons . Il cons ha due campi: il car , una reference ai dati di quel nodo, e il cdr , una reference al nodo successivo. Nonostante le celle cons possano essere utilizzate per costruire ulteriori strutture dati, questo è il loro scopo primario.
In altri linguaggi le liste concatenate sono tipicamente costruite tramite reference e record . Di seguito vi è un esempio completo in C :
#include <stdio.h> /* per printf */
#include <stdlib.h> /* per malloc */
typedef struct ns {
int data ;
struct ns * next ;
} node ;
node * list_add ( node ** p , int i ) {
node * n = ( node * ) malloc ( sizeof ( node ));
n -> next = * p ;
* p = n ;
n -> data = i ;
return n ;
}
void list_remove ( node ** p ) { /* rimuove head */
if ( * p != NULL ) {
node * n = * p ;
* p = ( * p ) -> next ;
free ( n );
}
}
node ** list_search ( node ** n , int i ) {
while ( * n != NULL ) {
if (( * n ) -> data == i ) {
return n ;
}
n = & ( * n ) -> next ;
}
return NULL ;
}
void list_print ( node * n ) {
if ( n == NULL ) {
printf ( "la lista è vuota \n " );
}
while ( n != NULL ) {
printf ( "print %p %p %d \n " , n , n -> next , n -> data );
n = n -> next ;
}
}
int main ( void ) {
node * n = NULL ;
list_add ( & n , 0 ); /* lista: 0 */
list_add ( & n , 1 ); /* lista: 1 0 */
list_add ( & n , 2 ); /* lista: 2 1 0 */
list_add ( & n , 3 ); /* lista: 3 2 1 0 */
list_add ( & n , 4 ); /* lista: 4 3 2 1 0 */
list_print ( n );
list_remove ( & n ); /* rimuove il primo elemento (4) */
list_remove ( & n -> next ); /* rimuove il nuovo secondo (2) */
list_remove ( list_search ( & n , 1 )); /* rimuove la cella che contiene 1 (primo) */
list_remove ( & n -> next ); /* rimuove il successivo (0) */
list_remove ( & n ); /* rimuove l'ultimo (3) */
list_print ( n );
return 0 ;
}
Immagazzinamento dei dati all'interno o all'esterno della lista
Costruendo una lista concatenata, ci si trova di fronte alla scelta se immagazzinare i dati direttamente nei nodi della lista, metodo chiamato internal storage , o immagazzinare solamente la reference al dato, chiamato external storage . L' Internal storage ha il vantaggio di rendere l'accesso ai dati più efficiente, poiché richiede meno spazio totale, a causa della migliore località della referenza , e semplificando la gestione della memoria della lista ( i suoi dati sono allocati e liberati nello stesso tempo dei nodi della lista).
L' external storage , d'altro canto, ha il vantaggio di essere più generico, poiché le stesse strutture ed il codice macchina possono essere riutilizzate per un'altra lista concatenata, dal momento che non occorre preoccuparsi della dimensione dei dato. Risulta anche facile immettere gli stessi dati in più liste concatenate. Nonostante sia possibile porre gli stessi dati, tramite una memoria interna, in molteplici liste includendo references next multiple in ogni nodo, sarebbe necessario creare routine separate per aggiungere o cancellare celle basate su ogni campo. È possibile creare liste concatenate addizionali composte di elementi che utilizzino la memoria interna per custodire le reference al nodo della lista concatenata che contiene i dati.
In generale, se un insieme di strutture dati necessita di essere incluso in molteplici liste concatenate, l' external storage è la soluzione migliore. Se un insieme di strutture dati necessita di essere incluso solo in una lista, l' internal storage è leggermente meglio, a meno che sia disponibile un package generico di liste concatenate che implementi l' external storage . Allo stesso modo, se diversi insiemi di dati che possono essere immagazzinati nella stessa struttura dati possono essere inclusi in una singola lista concatenata, allora va bene l' internal storage .
Un altro approccio può essere utilizzato con alcuni linguaggi che hanno diverse strutture dati, ma tutti con lo stesso campo iniziale, includendo le referenze al next (e prev se abbiamo una lista doppiamente concatenate) nella stessa locazione. Dopo aver definito strutture dati separate per ogni tipo di dato, viene definita una struttura generica che contiene il minimo ammontare di dati condivisi da tutte le altre strutture e contenute al top ( inizio ) delle strutture. Allora possono essere create le routine generiche che utilizzano la struttura minimale che implementa le operazioni della lista, ma routine separate per dati specifici. Questo approccio è usato spesso per routine per il parsing dei messaggi, quando vengono ricevuti vari tipi di messaggio, ma tutte iniziano con lo stesso insieme di campi, normalmente includendo un campo per il tipo di messaggio. Le routine generiche sono utilizzate per aggiungere nuovi messaggi ad una coda quando vengono ricevuti e rimuoverli dalla coda per maneggiarli. Il tipo di messaggio è utilizzato per chiamare la corretta routine in grado di maneggiare quello specifico tipo di messaggio
Esempi di immagazzinamento esterno e interno
Supponiamo di voler creare una lista concatenata di famiglie e dei loro membri. Usando l'immagazzinamento interno, la struttura potrebbe apparire come la seguente:
record member { // membro di una famiglia
member next
string firstName
integer age
}
record family { // la famiglia stessa
family next
string lastName
string address
member members // testa della lista dei membri della famiglia
}
Per stampare una lista completa delle famiglie e dei loro membri usando l'immagazzinamento interno, potremmo scrivere:
aFamily := Families // inizia alla testa della lista della famiglia
while aFamily ≠ null { // itera attraverso la lista della famiglia
stampa le informazioni riguardanti la famiglia
aMember := aFamily.members // restituisce la lista dei membri della famiglia
while aMember ≠ null { // itera attraversa la lista dei membri
stampa le informazioni riguardanti il membro della famiglia
aMember := aMember.next
}
aFamily := aFamily.next
}
Usando l'immagazzinamento esterno, potremmo creare le seguenti strutture:
record node { // struttura per un nodo generico
node next
pointer data // puntatore generico per i dati del nodo
}
record member { // struttura per i membri della famiglia
string firstName
integer age
}
record family { // struttura per la famiglia
string lastName
string address
node members // testa della lista dei membri di questa famiglia
}
Per stampare una lista completa delle famiglie e dei loro membri usando l'immagazzinamento esterno, potremmo scrivere:
famNode := Families // inizia alla testa della lista della famiglia
while famNode ≠ null { // itera attraverso la lista delle famiglie
aFamily = (family)famNode.data // estrae la famiglia dal nodo
stampa le informazioni riguardanti la famiglia
memNode := aFamily.members // restituisce la lista dei membri della famiglia
while memNode ≠ null { // itera attraversa la lista dei membri
aMember := (member)memNode.data // estrae il membro della famiglia dal nodo
stampa le informazioni riguardanti il membro della famiglia
memNode := memNode.next
}
famNode := famNode.next
}
Si nota che quando si usa l'immagazzinamento esterno. è necessario un passo in più per estrarre il record dal nodo e fare il cast verso il tipo di dato opportuno. Questo avviene perché sia la lista delle famiglie che la lista dei membri della famiglia sono memorizzate in due liste concatenate che usano la stessa struttura dati ( node ).
Fino a quando un membro può appartenere soltanto a una famiglia, l'immagazzinamento interno funziona bene. Se, invece, la collezione di dati si riferisce a generazioni multiple, così che una persona può apparire come figlio in una famiglia, ma genitore in un'altra, si rende necessario l'immagazzinamento esterno.
Velocizzare le ricerche
L'individuazione dell'elemento specifico in una lista concatenata anche se è ordinata, richiede normalmente un tempo O( n ) ( ricerca ordinata ). Questo è uno degli svantaggi fondamentali delle liste concatenate rispetto alle altre strutture dati. In aggiunta alle varianti discusse nella sezione precedente, ci sono vari semplici modi per migliorare il tempo di ricerca.
In una lista non ordinata, una semplice euristica per diminuire il tempo di ricerca medio è la move-to-front heuristic , che semplicemente sposta un elemento all'inizio della lista una volta che questo è stato trovato. Questo schema, pratico per la creazione di semplici caches , assicura che l'elemento usato più di recente sia anche il più veloce da ritrovare.
Un altro approccio comune è quello di indicizzare una lista collegata usando una struttura dati esterna più efficiente. Per esempio, si può costruire un red-black tree o una hash table i cui elementi sono riferimenti ai nodi della lista collegata.
Possono essere aggiunti ad una lista molti di questi indici. Lo svantaggio è che questi indici necessitano di essere aggiornati ogni volta che si aggiunge o rimuove un nodo ( o ogni volta che l'indice viene utilizzato di nuovo)
Altre strutture collegate
Sia le pile che le code sono spesso implementati utilizzando liste concatenate, e spesso il loro uso viene ristretto al tipo di operazioni che supportano.
La skip list è una lista concatenata a cui sono stati aggiunti livelli di puntatori per raggiungere velocemente un gran numero di elementi e quindi discendere al livello successivo. Il processo continua fino all'ultimo livello che la lista vera e propria.
Un albero binario può essere descritto come un tipo di lista concatenata dove gli elementi sono essi stessi liste concatenate dello stesso tipo. Il risultato è che ogni nodo può includere un riferimento al primo nodo di una o due altre liste concatenate, che, insieme al loro contenuto, forma il sottoramo del nodo.
Una unrolled linked list è una lista concatenata in cui ogni nodo contiene un vettori di dati. Ciò conduce ad un miglioramento del funzionamento della cache, dal momento che un maggior numero di elementi si trova in un'area contigua della memoria e riduce l'utilizzo di memoria, dal momento che devono essere inclusi meno metadata in ogni elemento della lista.
Un' hash table può utilizzare liste concatenate per memorizzare le catene di oggetti che hanno il medesimo hash.
Bibliografia
- National Institute of Standards and Technology (August 16, 2004). Definizione di una lista concatenata . Retrieved December 14, 2004.
- Antonakos, James L. and Mansfield, Kenneth C., Jr. Practical Data Structures Using C/C++ (1999). Prentice-Hall. ISBN 0-13-280843-9 , pp. 165–190
- Collins, William J. Data Structures and the Java Collections Framework (2002, 2005) New York, NY: McGraw Hill. ISBN 0-07-282379-8 , pp. 239–303
- Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford Introductions to Algorithms (2003). MIT Press. ISBN 0-262-03293-7 , pp. 205–213, 501–505
- Green, Bert F. Jr. (1961). Computer Languages for Symbol Manipulation. IRE Transactions on Human Factors in Electronics. 2 pp. 3–8.
- McCarthy, John (1960). Recursive Functions of Symbolic Expressions and Their Computation by Machine, Part I. Communications of the ACM . [1] HTML DVI PDF PostScript
- Donald Knuth . Fundamental Algorithms , Third Edition. Addison-Wesley, 1997. ISBN 0-201-89683-4 . Sections 2.2.3–2.2.5, pp. 254–298.
- Thomas H. Cormen , Charles E. Leiserson , Ronald L. Rivest , and Clifford Stein . Introduction to Algorithms , Second Edition. MIT Press and McGraw-Hill, 2001. ISBN 0-262-03293-7 . Section 10.2: Linked lists, pp. 204–209.
- Newell, Allen and Shaw, FC (1957). Programming the Logic Theory Machine. Proceedings of the Western Joint Computer Conference. pp. 230–240.
- Parlante, Nick (2001). Linked list basics. Stanford University . PDF
- Sedgewick, Robert Algorithms in C (1998). Addison Wesley. ISBN 0-201-31452-5 , pp. 90–109
- Shaffer, Clifford A. A Practical Introduction to Data Structures and Algorithm Analysis (1998). NJ: Prentice Hall. ISBN 0-13-660911-2 , pp. 77–102
- Wilkes, Maurice Vincent (1964). An Experiment with a Self-compiling Compiler for a Simple List-Processing Language. Annual Review in Automatic Programming 4 , 1. Published by Pergamon Press.
- Wilkes, Maurice Vincent (1964). Lists and Why They are Useful. Proceeds of the ACM National Conference, Philadelphia 1964 (ACM Publication P-64 page F1-1); Also Computer Journal 7 , 278 (1965).
- Kulesh Shanmugasundaram (April 4, 2005). Spiegazione delle liste concatenate del Kernel Linux .
Voci correlate
Altri progetti
-
 Wikimedia Commons contiene immagini o altri file su lista concatenata
Wikimedia Commons contiene immagini o altri file su lista concatenata
Collegamenti esterni
- Del materiale sulle liste concatenate è disponibile alla Stanford University dipartimento di informatica:
- ( EN ) Introduzione alle liste concatenate , su cslibrary.stanford.edu .
- ( EN ) Problemi sulle liste concatenate , su cslibrary.stanford.edu .
- ( EN ) Citazioni da CiteSeer , su citeseer.ist.psu.edu .
- ( EN ) Apprendere le liste , su acmacs.com . URL consultato il 17 luglio 2006 (archiviato dall' url originale il 28 giugno 2006) .
- ( EN ) Implementazioni delle shared singly linked list , su cs.chalmers.se .
- ( EN ) Introduzione alle liste concatenate con diagrammi e esempi di codice in Java , su mycsresource.net . URL consultato il 17 luglio 2006 (archiviato dall' url originale il 27 settembre 2007) .
| Controllo di autorità | GND ( DE ) 4783888-7 |
|---|