Web semantic
Cu termenul de Semantic Web , un termen inventat de inventatorul său, Tim Berners-Lee , este reformarea World Wide Web într-un mediu în care documentele publicate (pagini HTML , fișiere , imagini etc.) sunt asociate cu informații și date ( metadate ) care specifică contextul semantic într-un format adecvat și interpretarea întrebării (de exemplu, prin intermediul motoarelor de căutare ) și, mai general, toate „ procesările automate ”.
Odată cu interpretarea conținutului documentelor pe care Web-ul semantic le impune, vor fi posibile căutări mult mai avansate decât cele actuale, pe baza prezenței în document a cuvintelor cheie și a altor operațiuni specializate precum construirea rețelelor de relații și conexiuni între documente conform mai multor logici.elaborați pe un hyperlink simplu.
Introducere
Pentru construcția / definiția sa s-ar putea gândi să folosim „ XML , un meta-limbaj care permite descrierea (și cu detaliile dorite) a diferitelor părți ale unui document. Un document astfel descris poate fi apoi procesat pentru diferite utilizări: extragerea informațiilor conform unor criterii specifice, reformulare mai mult sau mai puțin parțială pentru adaptarea la alte formate, afișare în funcție de capacitățile terminalului. Cu toate acestea, XML nu permite o definiție semantică adecvată, din motive pe care le vom specifica mai târziu.
Deși un document este o modalitate bună de a introduce informații, un document, chiar dacă este exprimat în format XML, este inadecvat pentru Web, care prin natura sa este descentralizat, distribuit și, prin urmare, informațiile despre o anumită entitate pot fi localizate oriunde .
De fapt, cu XML este posibil să se descrie în mod adecvat conținutul unui document, dar sintaxa XML nu definește niciun mecanism explicit pentru a califica relațiile dintre documente. Acest lucru nu ajută nici măcar mecanismul hyperlink - urilor popularizat de „ HTML deoarece amorf, care nu permite descrierea relației definite.
Cu alte cuvinte, deși într-un document (de exemplu, o pagină HTML) este posibil să se vorbească despre un domn Ciampi și să se exprime semantic acest lucru cu etichete adecvate, atunci este dificil de înțeles dacă două documente care se referă la un domn Ciampi se referă la aceeași persoană, rezultând o calitate slabă a rezultatelor returnate de motoarele de căutare .
În cel mai bun caz, ar fi posibil să se deducă dacă, printre altele, au existat date semantic definite și suficient de precise (de exemplu, Codul fiscal ) sau hyperlinkuri descrise corespunzător care le conectează.
Cu toate acestea, întrucât diferitele documente sunt scrise în scopuri diferite, independent unul de celălalt și în mod normal fără a partaja un format XML comun, informațiile utile precum adresa poștală sau data nașterii ajung să fie exprimate într-un mod diferit și neuniform. Adresa într-un caz poate fi pur și simplu închisă de etichetele <adresă>, în altele de <indirect_postale>, <direccion>, <adresă> sau < adresă >, și apoi să ia în considerare posibilitatea de a fi identificat explicit <document>, < zip_code> ... ceea ce face dificilă și nu fără risc orice deducere în mod automat.
În secțiunile următoare vom explica mai întâi limbajul folosit pentru a construi web-ul semantic, deci tendințele proiectate, instrumentele și contribuția pe care aceste tehnologii ar putea să o facă pentru a răspunde definitiv la una dintre problemele nerezolvate din calcul: managementul cunoștințelor corporative .
Primele limbi: RDF, N3
Evoluția rețelei web semantice începe cu definirea, de către W3C , a cadrului standard de descriere a resurselor (RDF), o anumită aplicație XML care standardizează definiția relațiilor dintre inspirația informațiilor din principiile logicii predicate (sau predicatul logic primul comandă) și apelând la instrumentele tipice de pe Web (de exemplu, URI ) și XML ( spațiu de nume ).
Pe scurt, în conformitate cu logica predicatului, informațiile sunt exprimabile cu enunțuri (enunț în engleză) constituite din triplu format din subiect, predicat și valoare (în engleză adesea identificate ca subiect, verb și respectiv obiect ). De exemplu, următoarele declarații ale unui președinte al Republicii Italiene:
- Domnul Ciampi locuiește la Roma.
- Ciampi cod fiscal CMPCLZ20T09E625V.
poate fi defalcat schematic ca
| Afirmația 1 | Afirmația 2 | |
| Subiect | Domnule Ciampi | Domnule Ciampi |
| Predicat | traieste in | are un cod fiscal |
| Valoare | Roma | CMPCLZ20T09E625V |
apoi pentru unele dintre aceste elemente puteți fi găsit în mod arbitrar pe URI - ul web care le identifică (resurse) în mod unic, cum ar fi:
| Domnule Ciampi | http://presidenti.quirinale.it/Ciampi/cia-biografia.htm |
| traieste in | https://en.wiktionary.org/wiki/vivere |
| Roma | http://www.comune.roma.it |
| Are un cod fiscal | https://it.wikipedia.org/wiki/codice_fiscale |
În acest caz, pentru
- Domnul Ciampi a ales să facă referire la biografia sa disponibilă pe site-ul oficial al Quirinale
- Roma a ales să utilizeze site-ul web al Orașului Romei
- Lives in ați ales să faceți referire la definiția verbului live disponibil pe Wikționar
- are codul fiscal pe care l-ați ales să faceți referire la definiția codului fiscal este disponibilă pe Wikipedia
În următoarele câteva paragrafe descrie cum să formalizăm propozițiile anterioare în RDF în forma sa canonică , în cele două formate textuale alternative ( N3 și N3 cu prefixe) și grafic.
Trebuie remarcat faptul că programele speciale precum IsaViz [1] W3C vă permit să treceți de la un format la altul și sunt utile pentru testarea semanticului web.
Soluție RDF canonică
O posibilă formalizare a exemplului în RDF este:
1. <? Xml version = "1.0"?> 2. <rdf: RDF 3. xmlns: rdf = " http://www.w3.org/1999/02/22-rdf-syntax-ns# " 4. xmlns: wikipedia = " http://it.wikipedia.org/wiki/ " 5. xmlns: Wiktionary = " http://it.wiktionary.org/wiki/ "> 6. <rdf: Descriere 7. rdf: about = " http://www.quirinale.it/qrnw/statico/ex-presidenti/Ciampi/cia-biografia.htm "> 8. <wiktionary: a trăi 9. rdf: resource = " http://www.comune.roma.it/index.asp " 10. /> 11. </ rdf: Descriere> 12. <rdf: Descriere 13. rdf: about = " http://www.quirinale.it/qrnw/statico/ex-presidenti/Ciampi/cia-biografia.htm "> 14. <wikipedia: tax_code> 15. CMPCLZ20T09E625V 16. </ wikipedia: tax_code> 17. </ rdf: Descriere> 18. </ rdf: RDF>
| Rândul 1 | <? xml version = '1.0'?>, antet standard XML | |
| Rândul 2 | rdf: RDF este rădăcina unui nod de document RDF definit în spațiul de nume rdf menționat la rândul 3 | |
| Rândul 3 | xmlns: rdf = face referire la spațiul de nume standard al sintaxei RDF , identificându-l ca rdf. Rețineți că în XML definiți un spațiu de nume pentru a face codul de scriere concis. De acum înainte, de fapt, de fiecare dată când întâlnești rdf: acesta trebuie înlocuit (mental) cu ceea ce este scris în dreapta lui '= a acestei expresii, așa cum sa făcut deja în rândul 2. | |
| Rândul 4 și 5 | xmlns: wikipedia = e xmlns: Wiktionary = două referințe suplimentare la acest spațiu de nume, identificându-le ca wikipedia și Wiktionary | |
| Liniile 6-11 | Ei definesc „afirmația pe care domnul Ciampi o trăiește la Roma | |
| Rândul 6 | rdf: Descrierea spațiului de nume rdf este eticheta la care se face referire la linia 3 care specifică o declarație „ (subiect, predicat, valoare) | |
| Rândul 7 | rdf: about este un atribut al Descrierii Riga 6 care trebuie utilizat pentru a specifica subiectul unei afirmații atunci când, ca în acest caz, este un URI | Domnule Ciampi |
| Rândul 8 | live este eticheta definită în spațiul de nume Wiktionary listat în rândul 4, folosit pentru a defini predicatul | traieste in |
| Rândul 9 | rdf: resursa este un identificator al rdf-ului menționat la spațiul de nume Linia 3 pentru a specifica valoarea afirmației, atunci când este exprimat ca un URI | Roma |
| Rândul 10 | definirea închiderii unui tag XML gol | |
| Rândul 11 | Descriere Închide eticheta deschisă la Riga 6 | |
| Rândul 12-17 | Ei definesc „afirmația dlui Ciampi cod fiscal CMPCLZ20T09E625V | |
| Rândul 12 | rdf: Descrierea spațiului de nume rdf este eticheta la care se face referire la linia 3 care specifică o declarație „ (subiect, predicat, valoare) | |
| Rândul 13 | rdf: about este un atribut al liniei de descriere 12 care trebuie utilizat pentru a specifica subiectul unei declarații atunci când, ca în acest caz, este un URI | Domnule Ciampi |
| Rândul 14 | „Codice_fiscale este eticheta definită în spațiul de nume Wikipedia stabilit în rândul 4, utilizat pentru a defini predicatul | Are un cod fiscal |
| Rândul 15 | Valoarea Afirmația dell“ | CMPCLZ20T09E625V |
| Rândul 16 | Închide elementul deschis 14 la Riga | |
| Rândul 17 | Descriere Închide eticheta pentru a deschide Linia 12 | |
| Rândul 18 | Închide elementul rădăcină RDF deschis la rândul 2 | |
Deoarece cele două fraze au același subiect, atunci pot fi reformulate astfel:
- Domnul Ciampi locuiește la Roma și are un cod fiscal CMPCLZ20T09E625V
care corespunde unei formalizări RDF la fel de sintetice (și echivalente cu precedentul):
<? xml version = '1.0'?> <rdf: RDF xmlns: rdf = " http://www.w3.org/1999/02/22-rdf-syntax-ns# " xmlns: wikipedia = " http://it.wikipedia.org/wiki/ " xmlns: wikidizionario = " http://it.wiktionary.org/wiki/ "> <rdf: Descriere rdf: about = " http://www.quirinale.it/qrnw/statico/ex-presidenti/Ciampi/cia-biografia.htm " "> <wikidtionary: a trăi rdf: resource = " http://www.comune.roma.it/index.asp " /> <wikipedia: tax_code> CMPCLZ20T09E625V </ wikipedia: tax_code> </ rdf: Descriere> </ rdf: RDF>
Soluție grafică
Pentru a grafica declarațiile RDF, utilizați grafice alegând nodurile după subiect și valoare, unite de o margine direcționată de la subiect la valoare pentru predicat.
Unele aplicații, cum ar fi IsaViz menționat anterior , utilizate în acest exemplu, adoptă elipse pentru noduri care sunt URI ( http://www.comune.roma.it/index.asp ), altfel dreptunghiurile pentru noduri care conțin șiruri simple de caractere (CMPCLZ20T09E625V). Acestea fiind spuse, în exemplul nostru corespunde graficului :

Soluția N3
N3 (cunoscut și ca N-tripluri sau Notația 3) propune o formă mai ușor de citit decât la RDF și exemplul pe care îl luăm în considerare este următoarea soluție:
< Http://www.quirinale.it/qrnw/statico/ex-presidenti/Ciampi/cia-biografia.htm "> < Https://it.wiktionary.org/wiki/vivere > < Http://www.comune.roma.it/index.asp >. < Http://www.quirinale.it/qrnw/statico/ex-presidenti/Ciampi/cia-biografia.htm "> < Https://it.wikipedia.org/wiki/codice_fiscale > „CMPCLZ20T09E625V”.
Fiecare enunț poate fi scris și pe o singură linie, punând subiect, predicat și valoare unul după altul. Amintiți-vă că N3 este, de asemenea, semnificativ. ( Punct ) care marchează sfârșitul fiecărei afirmații.
Soluția N3 cu prefixe
N3 cu prefixe (N3 cu prefix în dicția engleză) este și mai sintetic N3 și preia ideea de spațiu de nume XML pentru a facilita compilarea folosind un editor simplu. În acest caz, exemplul este tradus prin:
@prefix Președinte: http://www.quirinale.it/presidente/ @prefix wikipedia: https://it.wikipedia.org/wiki/ @prefix wikidizionario: https://it.wiktionary.org/wiki/ @prefix comune_roma: http://www.comune.roma.it/ Președinte: ciampi.html wikidizionario: living comune_roma: index.asp. Președinte: ciampi.html wikipedia: codice_fiscale "CMPCLZ20T09E625V".
În cazul în care comanda @prefix definește înlocuirea constantă a instrumentelor automate specifice care se ocupă de lucru pentru a completa declarațiile care le folosesc. Ca și în cazul N3, chiar și pentru N3 cu prefixe este semnificativ. (perioada) la sfârșitul fiecărei declarații.
BUFNIŢĂ
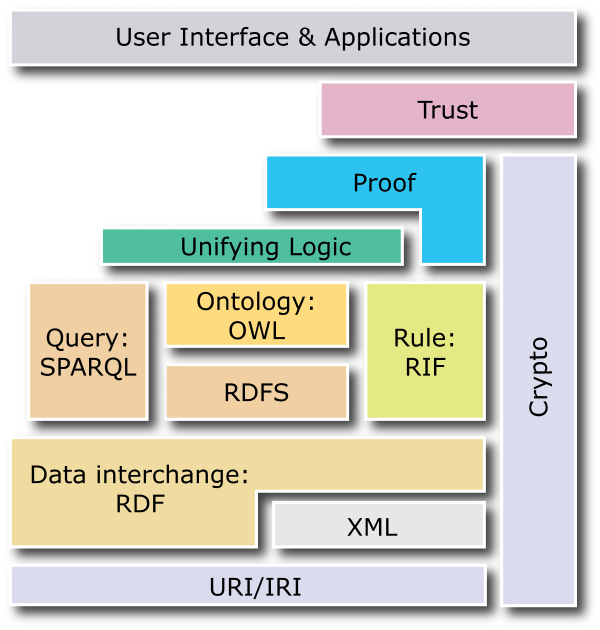
RDF este doar primul pas. Web-ul semantic este construit în straturi:

Logica predicativă a primului ordin este extrem de complexă, iar RDF ar putea exprima o porțiune foarte mică a acestuia. Nu numai asta: această logică, dacă este luată în ansamblu, nu este nici măcar calculabilă, în timp ce logica alcătuită din subseturi ale operatorilor logicii de ordinul întâi poate fi calculabilă. Aceste subseturi de logică formală sunt studiate de logica de descriere , sau logica de descriere, iar una dintre acestea a fost adoptată pentru formularea unui nou standard, mai bogat și mai expresiv decât RDF: OWL . OWL oferă multe construcții noi, două dintre acestea, foarte ușor de înțeles, sunt „echivalența dintre resurse și relația inversă .
- Pentru echivalența dintre resurse se referă la capacitatea de a spune că două sau mai multe URI reprezintă același element.
- A inversa este capacitatea de a spune că, dacă este adevărat (subiect, predicat, obiect), atunci este și adevărat (obiect, predicato_inverso, subiect).
Importanța unui construct ca „echivalență” este explicată în curând doar luând în considerare exemplele de mai sus. De exemplu. pentru a putea declara că
CF: CMPCLZ20T09E625V, wikipedia: carlo_azeglio_ciampi și quirinale: ciampi.htm sunt echivalente
ne-ar permite să înțelegem că afirmațiile
CF: CMPCLZ20T09E625V numit „Carlo Azeglio Ciampi” wikipedia: carlo_azeglio_ciampi locuiește la Roma quirinale: ciampi.htm este un „Prezidențial”
formalizat în mod corespunzător și găsit peste tot se referă la aceeași resursă, un președinte al Republicii (orice ar însemna asta sau orice se poate deduce din aceste informații) care locuiește la Roma și se numește Carlo Azeglio Ciampi.
În ceea ce privește „inversul”, în schimb , doar gândiți-vă că, atunci când spunem că fratele lui Romulus Remo, înseamnă , de asemenea, că Remo este fratele lui Romulus, pretinde că face explicit în RDF pentru a fi cunoscut de sistem. Operațiune fezabilă, dar plictisitoare. Pentru a evita acest lucru, ar fi suficient să se definească odată pentru totdeauna că dacă X este fratele lui Y, atunci este adevărat și Y este fratele lui X.
Aceste construcții, împreună cu altele, au fost introduse mai întâi de limbaje anterioare sau contemporane, cum ar fi RDF DAML (definit de DARPA american) și ILO (sponsorizat de Uniunea Europeană în cadrul programului IST ), ulterior fuzionat în DAML + OIL . Pe această bază, W3C a numit OWL ( Web Ontology Language ).
OWL există în trei forme, caracterizate prin diferite grade de complexitate și - în consecință - de calculabilitate . OWL-Lite este calculabil (că puteți găsi toate soluțiile în timp finit), dar o expresie redusă; OWL-Lite este rar folosit deoarece există OWL-DL, care este la fel de calculabil, dar mai bogat. În cele din urmă există OWL-Full, acoperind toată bogăția logicii predicate, dar nu este calculabilă și, prin urmare, nu este adecvată raționamentului automat.
Cu OWL puteți scrie ontologiile care descriu cunoștințele pe care le avem despre un anumit domeniu, prin clase, relații între clase și indivizi din clase. Cunoștințele astfel formalizate sunt procesabile automat de un computer, folosind un Raționament semantic care implementează procesele inferențiale și deductive.
Cum se folosește
Din exemplele de mai sus arată că o condiție necesară pentru utilizarea cu succes a RDF este disponibilitatea online a referințelor de calitate la URI-ul utilizat / referențiat. În special, este important ca aceste resurse să fie cunoscute, partajate și stabile în timp. De exemplu, referința utilizată pentru a-l identifica pe președintele Ciampi, din acest punct de vedere, nu este cea mai bună, deoarece este valabilă doar în timpul mandatului prezidențial, după care va fi mutată la http://www.quirinale.it/qrnw/statico / ex- Presidents / Ciampi / cia-biografia.htm unde există deja cele ale predecesorilor săi.
După această dată declarația va rămâne valabilă, dar va pierde contribuția informativă a paginii de referință de pe web utilă pentru o interpretare a acesteia.
Mult mai potrivit ar fi să folosim biografia definită în Wikipedia sau în Codul fiscal cu, de exemplu,
Deși acest URI de astăzi nu se referă la nimic de pe web, acesta ar putea fi în continuare utilizat în acest scop deoarece RDF nu presupune nicio verificare a disponibilității reale a resursei în sine. În acest fel, toate persoanele fizice și juridice contemporane și nu numai personalitățile, companiile, entitățile și instituțiile „importante” ar putea fi identificate în mod unic, sporind în mare măsură posibilitățile RDF (în orice caz, nimic nu ar interzice agenției de venituri să ofere un serviciu care , pornind de la URI-ul menționat anterior, returnează automat informațiile personale relative).
Acestea fiind spuse, s-ar putea argumenta că:
- Resursa identificată prin codul fiscal CMPCLZ20T09E625V locuiește la Roma, are o biografie în https://it.wikipedia.org/wiki/carlo_azeglio_ciampi și alta în http://www.quirinale.it/presidente/ciampi.htm
adică:
Agenția @prefix: https://web.archive.org/web/20050212035111/http://www.agenziaentrate.it/servizi/ @prefix comune_roma: http://www.comune.roma.it/ @prefix Președinte: http://www.quirinale.it/presidente/ @prefix wikipedia: https://it.wikipedia.org/wiki/ @prefix wikidizionario: https://it.wiktionary.org/wiki/ agenție: CF # CMPCLZ20T09E625V wiktionary: common living_rome: index.asp agenție: CF # CMPCLZ20T09E625V Wikționar: președinte biografie: ciampi.htm agenție: CF # CMPCLZ20T09E625V Wikipedia: biografie Wikipedia: carlo_azeglio_ciampi
Un alt truc pe care trebuie să-l țineți cont atunci când alegeți termenii care vor fi utilizați pentru definirea relațiilor este să folosiți dicționare care sunt deja cunoscute și răspândite, în loc să inventați de fiecare dată noi. De exemplu. informațiile demografice personale pentru cartea de vizită tipică, cum ar fi numele, adresa, e-mailul, rolul companiei ... sunt deja disponibile vCard [3] . Se uită chiar și numeroasele aplicații XML definite pentru a permite EDI ( schimbul electronic de date, schimbul electronic de date) în cadrul administrației publice ( e-guvernare ) sau a asociațiilor din industrie.
Din cele explicate până acum, este ușor de înțeles că, în construcția web-ului semantic, proiectele precum Wikipedia sau Wiktionary nu sunt doar funcționale, ci sunt exploatate în mod adecvat, permițând, de asemenea, deoarece oferă termeni bine documentați pentru identificarea resurselor. și predicate, garantând stabilitatea lor în timp și, mulțumită posibilității de a declara echivalențe în aceeași limbă și între diferite limbi, pentru a crește în continuare amploarea unui sondaj automat.
Instrumente
Evident, nu este suficient să aveți o singură sintaxă pentru a exprima predicate. Pentru a face ceea ce sa spus până acum concret și util, avem nevoie, de asemenea, de instrumente capabile să gestioneze un set de afirmații pentru a răspunde solicitărilor utilizatorilor.
În ceea ce privește N3, majoritatea acestor instrumente, după cum puteți ghici din exemplele N3 și N3 cu prefixe, stochează afirmațiile într-unul sau mai multe tabele într-o bază de date relațională . Unele dintre aceste soluții au fost înregistrate de proiectul SWAD-Europe sponsorizat de Uniunea Europeană ca parte a IST .
Cu toate acestea, documentele scrise în OWL (sau ontologii ) puteți efectua o deducere reală a raționamentului deductiv, făcută de raționari automatizați.
Limbi de interogare
Pentru a utiliza bazele de cunoștințe formalizate conform acestor standarde, este necesar un limbaj pentru a le interoga. SPARQL (Simple Protocol And RDF Query Language) este unul dintre limbajele definite pentru interogarea sistemelor care gestionează instrucțiunile RDF. Până în prezent, există alte limbi echivalente funcțional, dar SPARQL este un candidat pentru a deveni o recomandare W3C [4] .
Pentru a interoga OWL, totuși, lipsește un standard, iar raționarii individuali implementează limbaje de interogare proprietare.
Web semantic și gestionarea cunoștințelor
Din cele de mai sus, veți înțelege de ce, dacă „ XML abordează descrierea documentelor, RDF (și evoluția sa) este potrivit în special pentru reprezentarea datelor, oferind o metodă potențială capabilă să rezolve o problemă furnizată parțial doar cu instrumente software: managementul cunoștințelor corporative , capacitatea nu numai de a trata diferitele date de bază (produs, clienți, furnizori, angajați, ...) și de a clasifica documentele tehnice sau administrative (analiza pieței, specificațiile tehnice, standardele, procedurile ...), ci puteți chiar să gestionați conținutul acestor documente permițând, de exemplu, regăsirea informațiilor în funcție de nevoile specifice ale solicitantului, completând ceea ce este pus la dispoziție din diferite surse [5] .
În ceea ce privește datele master, ar fi foarte ușor să mapezi datele deja disponibile într-un RDBMS în instrucțiunile RDF - pentru fiecare tabel:
- cheile unice identifică o entitate;
- numele coloanelor pot fi predicate;
- conținutul coloanelor valorile.
În ceea ce privește documentele, prin XML, acestea ar putea fi refăcute pentru a obține declarațiile RDF necesare, folosind:
- alinierea, standardizată în mod normal în documentația tehnică;
- utilizarea dicționarelor comune (un anumit element este numit în același mod în documente diferite);
- Analiza lexicală .
Dar reformularea mai eficientă a structurilor de date existente este doar primul și cel mai simplu dintre avantajele pe care ni le oferă web-ul semantic. Prin ontologii avem posibilitatea de a exprima direct structura cunoștințelor noastre și de a permite mașinilor să proceseze automat cunoștințele în sine, nu mai mult doar informații simple. În acest fel, trecem de la un computer simplu (procesare automată a informațiilor) la un Epistematica : o procesare automată a cunoștințelor.
Perspective pentru viitor
Web-ul , așa cum este astăzi, necesită instrumente mai avansate, pentru o navigare rapidă și ușoară prin numeroasele documente până la publicarea datelor multimedia. Pentru viitor, web-ul semantic își propune să dea sens paginilor web și hyperlinkurilor, oferind posibilitatea de a căuta doar ceea ce este cu adevărat necesar. Rețeaua nu ne duce întotdeauna acolo unde ne-am aștepta, iar dificultățile de orientare sunt semnificative atunci când căutăm ceva și nu știm unde să-l găsim. Derularea printr-o cantitate lungă de directoare în căutarea informațiilor dorite este acum o apariție zilnică, mai ales atunci când căutarea implică un termen destul de comun. Cu Semantic Web putem adăuga paginilor noastre un sens complet, un sens care depășește cuvintele scrise, o „personalitate” care poate ajuta orice motor de căutare să identifice ceea ce căutăm pur și simplu pentru că este, aruncând, de fapt, alții care nu satisfac cererea noastră. Toate acestea nu în virtutea sistemelor de inteligență artificială , ci pur și simplu în virtutea unui marcaj de documente, a unui limbaj gestionabil de toate aplicațiile și a introducerii unor vocabulare specifice, adică seturi de propoziții la care pot fi asociate relații stabilite între elementele marcate. Pentru ca web-ul semantic să funcționeze, acesta trebuie să aibă informații structurate și reguli de deducere pentru a-l gestiona, pentru a combina informațiile solicitate de o interogare. Tim Berners-Lee a subliniat că un element cheie al web-ului semantic va fi prezența unor ontologii diferite. Dacă doriți un sistem dinamic care să se poată rafina și să funcționeze la o scară universală, va trebui să plătiți prețul pentru o anumită cantitate de inconsecvență. Începând din 2006, proiectul pentru realizarea rețelei semantice prin construirea ontologiilor a fost parțial revizuit. Într-un articol publicat în International Journal on Semantic Web and Information Systems [6] intitulat The Semantic Web Revisited [7] , Tim Berners-Lee , Nigel Shadbolt și Wendy Hall au redefinit unele dintre caracteristicile webului semantic în funcție de dinamica World Wide Web . Ideea a fost dezvoltarea și îmbunătățirea ontologiilor în mod colaborativ, prin intervenția comunităților de practică . Drept urmare, această nouă abordare a avut tendința mai multă de a se asigura că datele sunt structurate sub formă de date legate în loc de ontologii. În articolul din 2009 [8] este clar că datele legate sunt tratate ca niște piloni noi pe care să se construiască rețeaua semantică.
Agenți semantici
Trebuie remarcat faptul că se lucrează în prezent la extinderea posibilităților rețelei semantice prin aplicarea ideii de agenți semantici inteligenți (programe care pot explora în mod independent și interacționa cu sistemele informatice pentru, de exemplu, căuta informații). Rolul acestor agenți în rețeaua semantică este de a oferi capacități de inferență mai largi, realizând ceea ce a fost exprimat într-un articol din Scientific American de Tim Berners-Lee numit The Semantic Web, care promite un viitor în care Lucy prezintă mamei un examen medical prin utilizarea unor agenți capabili să „înțeleagă” patologia, centrele de contact sunt capabile să trateze și chiar să solicite o programare agenților săi, doar pentru a lăsa confirmarea deciziei [9] .
Limite
Inexactitatea sistemului este prețul de plătit universalității sale, mesajele „nu se găsesc” (nu se găsesc) nu vor fi complet eliminate. Toate acestea pentru a face posibilă combinarea mai multor referințe și, prin urmare, să nu pierdem, cel puțin într-o linie programatică, posibilitatea unor definiții multiple, înțelegeri multiple ale aceluiași obiect concret.
O altă problemă foarte importantă și dezbătută este cum să gestionăm încrederea în afirmații sau, mai exact, în autorii afirmațiilor.
Pentru a depăși problema certificării care ar fi necesară pentru a menține acuratețea ontologiilor, afirmațiile sunt transformate ele însele în termeni legați de autorul său prin rolul (proprietatea) „afirmă” care are pentru codomain termenul „Afirmație”. În acest fel este posibil să atribui acestui nou termen un subiect, un predicat și un obiect folosind relațiile normale. Prin acest proces, propoziții precum „paharul conține vin” sunt schimbate în propoziții precum „Marcați AFIRMĂ că paharul (Subiectul) conține (Predicat) ceva vin (Obiectul)”. Pentru a fi mai precis, 4 afirmații ar trebui incluse în ontologie:
- Marco - afirmă - Afirmație
- Afirmație - hasSubject - Glass
- Afirmație - hasPredicated - Conține
- Afirmație - hasObject - Wine
Notă
- ^ IsaViz pe w3.org
- ^ Imagine a w3.org
- ^(EN) Reprezentarea obiectelor vCard în RDF / XML
- ^(EN) Limbaj de interogare SPARQL pentru RDF, Recomandarea W3C 15 ianuarie 2008
- ^(RO) OWL Web Ontology Language Use Cases and Cerencies
- ^ International Journal On Semantic Web and Information Systems Depus la 5 martie 2012 în Internet Archive .
- ^ Http: //% 20Semantic% 20Web% 20Revisited http://eprints.ecs.soton.ac.uk/12614/1/real/OLD_Semantic_Web_Revisted.pdf Filed 27 octombrie 2011 în Internet Archive .
- ^ http://tomheath.com/papers/bizer-heath-berners-lee-ijswis-linked-data.pdf
- ^ Semantic Web
{kind=link}
Bibliografie
- Tim Berners-Lee, Arhitectura noului web, Feltrinelli, Milano, 2002
- Michael Daconta, The Semantic Web, Wiley Pub., Indianapolis, 2003
- Davies, John, Towards the semantic web, J. Wiley, Chichester-Hoboken, 2003
- Dieter Fensel, Spinning the Semantic Web, MIT Press, Cambridge, 2003
- Tim Berners-Lee, The Semantic Web , în „Scientific American”, mai 2001
- Luca Spinelli, despre prezentarea web semantică în „Login”, Gruppo Editoriale Infomedia , 2005
- Johan Hjelm, Creating the Semantic Web with RDF, Wiley, New York, 2001
Elemente conexe
- Bază de cunoștințe
- Date legate
- KQML , limbaj și protocol de comunicare utilizat pentru schimbul de informații și cunoștințe
- Logica descriptivă
- Ontologie (informatică)
- Resource Description Framework (RDF) standard pentru descrierea cunoștințelor pe web
- SKOS
- Tehnologie Hărți subiect pentru organizarea și reprezentarea cunoștințelor
- XML
- Cercetare web
Alte proiecte
-
 Wikimedia Commons contiene immagini o altri file su web semantico
Wikimedia Commons contiene immagini o altri file su web semantico
Collegamenti esterni
- ( EN ) Sito ufficiale , su w3.org .
- ( EN ) Web semantico , su Enciclopedia Britannica , Encyclopædia Britannica, Inc.
- ( EN ) Opere riguardanti Web semantico , su Open Library , Internet Archive .
- Rassegna stampa in tempo reale sul web semantico , su semanticism.org . URL consultato il 18 dicembre 2008 (archiviato dall' url originale il 26 dicembre 2008) .
- RDF Primer del W3C , su w3.org .
- Un sistema semantico che raccoglie riferimenti a risorse di pubblica utilità quali strumenti e documenti nell'area Semantic Web
- SWAD-Europe su W3C , su w3.org .
- Websemantico.org .
- TermExtractor - software gratuito per l'estrazione di termini. Utile come punto di partenza per temi quali l' Ontologia
- Web Semantico e Rappresentazione della conoscenza : Percorso di studio introduttivo.
| Controllo di autorità | Thesaurus BNCF 48388 · LCCN ( EN ) sh2002000569 · GND ( DE ) 4688372-1 · BNF ( FR ) cb14521343b (data) · BNE ( ES ) XX553987 (data) |
|---|