Heteroskedasticitate
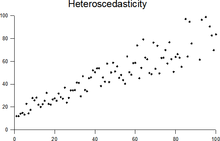
În statistici , un eșantion de variabile aleatorii este heteroskedastic (din grecul antic hetero „diferit” și „dispersie” skedasis ) dacă în cadrul acestuia există subpopulații care au variații diferite.
Caracteristica heteroskedasticității este deosebit de relevantă în contextul analizei de regresie, deoarece elimină unele ipoteze clasice ale modelului de regresie liniară .
În 2003 econometristul Robert Engle a câștigat Premiul Nobel pentru economie pentru studiile sale asupra analizei de regresie în prezența heteroskedasticității, la baza formulării modelelor clasei ARCH (din limba engleză Autoregressive Conditional Heteroskedasticity, conditioned heteroskedasticity autoregressive).
Regresiuni și termeni de eroare
În general, problema heteroskedasticității afectează termenii de eroare ai oricărui model cantitativ. Reziduurile din aceste modele (regresive sau autoregresive) sunt numite homoskedastice atunci când sunt statistic independente de toate variabilele explicative, când în schimb arată o tendință de a co-varia cu chiar și numai una dintre ele sunt definite ca heteroskedastice .
Probleme de estimare și interpretare
Heteroskedasticitatea implică o serie de complicații în estimarea și interpretarea unui model cantitativ. În ceea ce privește estimarea, aceasta implică ineficiența parametrilor de regresie calculați cu metoda obișnuită a celor mai mici pătrate (OLS) și, în consecință, necesitatea reestimării acestor parametri cu tehnici mai precise, de exemplu, cele mai mici pătrate generalizate (GLS) . Din punct de vedere al interpretării, heteroskedasticitatea poate sugera erori în faza de specificare a modelului. Să luăm de exemplu un model cu o singură variabilă explicativă care dorește să descrie tendința inflației Y pe măsură ce costul mașinilor X variază. Ar trebui formalizat după cum urmează:

Unde e reprezintă termenul de eroare pentru fiecare nivel al variabilelor. Dacă în urma unui test de heteroskedasticitate (de exemplu , testul lui White ) se evidențiază o corelație între erori și variabila X , atunci este foarte probabil ca parametrul b să fie nu numai ineficient, ci și distorsionat, deoarece suportă greutatea variabilei dependente de una sau mai multe variabile explicative omise. Conceptual, se poate spune că variabila X și constanta a reprezintă modelul cantitativ, adică poate explica realitatea observată. Termenul de eroare e reprezintă în schimb distanța dintre model și realitate, diferența dintre estimările obținute și observațiile efectiv făcute. Este de la sine înțeles că o legătură puternică între variabile și termenii de eroare evidențiază cât de mult poate fi ascunsă o componentă relevantă a fenomenului observat în acesta din urmă, ceea ce ar fi mai bine descris cu o altă specificație a modelului cantitativ. În exemplul prezentat, poate fi necesar să precizăm că inflația crește nu numai datorită prețului mașinilor X, ci și datorită prețului pe baril de țiței Z , atunci:

Și de aici treceți la noi specificații și teste de semnificație pentru a testa bunătatea noilor estimări ale parametrilor și reziduurilor.
Ineficiența asimptotică a celor mai mici pătrate obișnuite
Un estimator obținut cu metoda obișnuită a celor mai mici pătrate ( Ordinary Least Squares sau OLS în limba engleză) menține proprietățile corectitudinii , consistenței și distribuției normale asimptotice chiar și în cazul heterosedasticității erorilor. Cu toate acestea, nu mai este asimptotic eficient , adică varianța sa nu mai este minimul posibil [1] nici măcar folosind un eșantion ipotetic cu un număr practic infinit de observații.
Pentru a dovedi ineficiența, este suficient să se arate că, în cazul heteroskedasticității, varianța asimptotică reală a estimatorului nu corespunde varianței minime posibile. Luați în considerare următorul model de regresie liniară:

Metoda celor mai mici pătrate obișnuite presupune omosedasticitatea erorilor . Presupunând că și celelalte ipoteze ale celor mai mici pătrate obișnuite sunt valabile, matricea varianță-covarianță a erorilor va fi
![{\ displaystyle E [ee '] = E \ left [{\ begin {bmatrix} e_ {1} \\ e_ {2} \\\ vdots \\ e_ {n} \ end {bmatrix}} {\ begin {bmatrix } e_ {1} & e_ {2} & \ cdots & e_ {n} \ end {bmatrix}} \ right] = {\ begin {bmatrix} \ sigma ^ {2} & 0 & \ cdots & 0 \\ 0 & \ sigma ^ {2} & \ cdots & 0 \\ && \ vdots & \\ 0 & 0 & 0 & \ sigma ^ {2} \\\ end {bmatrix}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/36355edcd78b6c1b67202cacb3789fc40bfcdab2)
iar estimatorul OLS va fi

cu distribuție asimptotică

a cărei varianță asimptotică este minimă posibilă.
Să presupunem că erorile sunt de fapt heteroskedastice, adică au forma:
![{\ displaystyle E [ee '] = \ sigma ^ {2} V = \ sigma ^ {2} {\ begin {bmatrix} v_ {1} ^ {2} & 0 & \ cdots & 0 \\ 0 & v_ { 2} ^ {2} & \ cdots & 0 \\ && \ vdots & \\ 0 & 0 & 0 & v_ {n} ^ {2} \\\ end {bmatrix}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5882f42c01132f6ad7a336e43e71282c1c329bdc)
În acest caz, folosind metoda obișnuită a celor mai mici pătrate, adevărata varianță asimptotică a estimatorului ar fi
![{\ displaystyle \ mathrm {Var} [{\ hat {\ beta}} _ {OLS}] = E \ left [({\ hat {\ beta}} _ {OLS} - \ beta) ({\ hat {\ beta}} _ {OLS} - \ beta) '\ right] = (X'X) ^ {- 1} X'E [ee'] X (X'X) ^ {- 1}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6ecc84eab8579e15b41a2183e163b7ab3ef889af)
și deoarece erorile sunt heteroskedastice, o veți obține
![{\ displaystyle \ mathrm {Var} [{\ hat {\ beta}} _ {OLS}] = \ sigma ^ {2} (X'X) ^ {- 1} X'VX (X'X) ^ {- 1} \ neq \ sigma ^ {2} (X'X) ^ {- 1}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/99b246e58546d753c003bfd545f35fc98a18c6a6)
Această nouă varianță este diferită de cea (cea mai mică posibilă) obținută atunci când erorile sunt de fapt homoskedastice. Prin urmare, estimatorul nu mai este asimptotic eficient în cazul în care erorile sunt heteroskedastice, dar sunt considerate eronat ca homoskedastice.
O interpretare a rezultatului este că matricea V acționează ca o greutate pentru matricea regresorului X. Pentru simplitate, luați în considerare un model cu un singur regresor și interceptarea: partea centrală a varianței estimatorului va fi

Din care se deduce că observațiile care corespunde unei varianțe a erorii mai mari au o pondere mai mare în calculul varianței estimatorului. În schimb, metoda obișnuită a celor mai mici pătrate atribuie o greutate de 1 tuturor observațiilor. Rationamente similare pot fi aplicate unui model cu mai mult de un regresor.

Ilustrații
Problema heteroskedasticității poate apărea sub o mare varietate de ipoteze, până la punctul în care în cele mai frecvent utilizate manuale tratarea problemei se efectuează de obicei printr-o serie de exemple.
- Luați în considerare ipoteza în care unitățile statistice ale eșantionului sunt firme de dimensiuni diferite, al căror profit este măsurat; în general, nu există niciun motiv să ne așteptăm ca variația profitului să fie constantă de la observare la observare (dimpotrivă, este probabil ca firmele mai mari să aibă profituri mai mari, a căror variabilitate va fi mai mare în valoare absolută decât cea a profituri de dimensiuni mai mici);
- Heteroskedasticitatea este, de asemenea, o proprietate bine cunoscută a randamentelor istorice ale stocurilor: perioadele de volatilitate ridicată sunt urmate de perioadele de volatilitate relativ scăzută (clustere de volatilitate).
Notă
- ^ Mai precis, estimatorii obținuți cu metoda obișnuită a celor mai mici pătrate sunt estimatori de maximă probabilitate și, ca atare, varianța lor asimptotică atinge limita inferioară Cramér-Rao .
Bibliografie
- Greene, WH (1993), Econometric Analysis , Prentice-Hall, ISBN 0-13-013297-7 , un text general, considerat standardul pentru un curs universitar de econometrie (în engleză );
- Hamilton, JD (1994), Time Series Analysis , Princeton University Press ISBN 0-691-04289-6 , textul de referință pentru analiza seriilor temporale; conține o expunere introductivă a modelelor ARCH (în engleză ).
Elemente conexe
Alte proiecte
-
 Wikimedia Commons conține imagini sau alte fișiere despre Heteroskedasticity
Wikimedia Commons conține imagini sau alte fișiere despre Heteroskedasticity